What is Snowflake?
An overview of Snowflake, a cloud-based data warehouse platform. This article explains Snowflake's architecture, key features, and how it differs from traditional data warehouses. Learn about its separation of storage and compute, support for structured and semi-structured data, and built-in security features.


Introduction to Snowflake: Powering the AI Data Cloud Revolution
Snowflake is a cloud-based data warehousing system (though the founders argue it’s much more than just a data warehousing system, it’s a broader data management platform) designed to address the limitations of traditional data warehouses in the age of big data and cloud computing. Developed by a team with extensive experience in database technology, Snowflake aims to provide a solution that is scalable, flexible, and easy to use.
The Problem
Traditional data warehousing systems face several challenges in today’s data environment:
- They struggle to handle the increasing volume and variety of data, especially semi-structured data from sources like web applications, mobile devices, and IoT sensors.
- Their dependence on complex ETL pipelines and physical tuning doesn’t work well with the flexibility and freshness requirements of new types of semi-structured data and rapidly evolving workloads in the cloud.
- They require significant effort for maintenance, tuning, and upgrades.
Snowflake’s Solution
Snowflake addresses these issues through its unique architecture and feature set:
- Pure Software-as-a-Service: Snowflake offers a complete cloud-based solution, eliminating the need for hardware or software installation and management.
- Multi-clustered: The system uses multiple compute clusters (Virtual Warehouses) that can work independently on the same data.
- Transactional (Relational): Snowflake provides full support for ACID transactions and relational data models.
- Highly Scalable and Available: The architecture allows for seamless scaling of resources and ensures high availability through fault tolerance and online upgrades.
- Elastic System with Full SQL: Users can scale compute resources up or down instantly, while enjoying comprehensive SQL support.
- Built-in Extensions for Semi-structured and Schema-less Data: Snowflake natively supports semi-structured data types like JSON, Avro, and XML without requiring predefined schemas.
- Time Travel and Cloning: The system allows access to historical data and instant cloning of tables, schemas, or entire databases.
- End-to-End Security: Snowflake implements comprehensive security measures, including end-to-end encryption, secure data sharing, and role-based access control.
Storage vs Compute
Traditional data warehousing systems typically had a tightly coupled architecture where storage and compute resources were inseparable. This meant that the same machines responsible for storing the data were also tasked with processing queries.
These systems often relied on on-premises hardware, requiring significant upfront investment and ongoing maintenance. Scaling was complex and often meant upgrading entire systems, leading to inefficient resource utilization. Performance was limited by fixed hardware specifications, and handling multiple concurrent queries could cause significant slowdowns. While this approach worked well enough in the early days of data warehousing, it led to several significant challenges as data volumes grew and workloads became more complex.
Traditional Shared-Nothing Architecture
In a traditional shared-nothing architecture:
- Each node has its own CPU, memory, and storage
- Data is partitioned across nodes
- Queries are processed in parallel across these nodes
- Adding or removing nodes requires data redistribution
While this architecture scales well for certain workloads, it has limitations:
- Tight coupling of compute and storage resources
- Difficulty handling heterogeneous workloads efficiently
- Challenges with elasticity and online upgrades
Snowflake’s Architecture: A Multi-Cluster, Shared-Data Approach
Snowflake is an innovative cloud-based data warehousing solution that introduces a unique multi-cluster, shared-data architecture. At its core, Snowflake separates storage and compute resources, allowing for independent scaling and management of each component. This separation enables Snowflake to combine the best aspects of shared-nothing and shared-disk architectures.
This design consists of three main layers, each playing a crucial role in Snowflake’s performance, scalability, and ease of use.
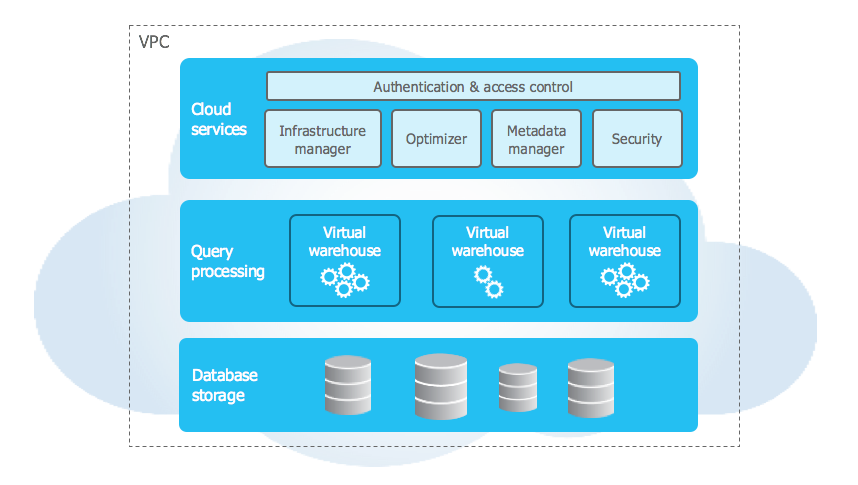
1. Data Storage Layer
Utilizing cloud object storage (such as Amazon S3, Azure Blob Storage, Google Cloud Storage), this layer stores table data and query results in a proprietary columnar format optimized for analytics.
Snowflake uses different blob storage services depending on the cloud platform:
- AWS: Amazon S3
- Azure: Azure Blob Storage
- GCP: Google Cloud Storage
Regardless of the storage service, Snowflake manages data in the same way:
- Data is reorganized into an optimized, compressed, columnar format
- Tables are horizontally partitioned into large, immutable files
- File headers contain metadata, including column offsets
But Snowflake doesn’t just dump your data into blog storage (ex: S3) as-is. It applies several optimizations:
- Micro-Partitioning: Data is automatically divided into small (50-500 MB), immutable micro-partitions. This fine-grained partitioning enables efficient pruning during queries.
- Columnar Storage: Within each micro-partition, data is stored in a columnar format. This allows for better compression and faster analytical queries.
- Data Clustering: Snowflake automatically collects metadata about the micro-partitions, which it uses for smart pruning during query execution.
- Automatic Optimization: The system continuously optimizes storage in the background, reorganizing data for better performance without any manual intervention.
2. Compute Layer (Virtual Warehouses)
Compute in Snowflake is provided through Snowflake’s (proprietary) shared-nothing engine. Virtual Warehouses are Snowflake’s compute clusters. Virtual Warehouses (VWs) are a key component of Snowflake’s architecture, providing the compute resources necessary for query execution and data manipulation. They handle query execution within elastic clusters of virtual machines.
- A Virtual Warehouse is a cluster of virtual machines (VMs), specifically Amazon EC2 instances in AWS deployments.
- Each VM within a VW is called a worker node.
- VWs are presented to a single user or group of users as an abstracted compute resource.
- VW sizes range from X-Small to 6X-Large, providing different levels of compute power.
- A virtual warehouse is an MPP (massively parallel processing) compute cluster.
- Each virtual warehouse is independent and doesn’t share compute resources with others.
- Virtual warehouses can be started and stopped as needed.
Virtual Warehouses (VWs) use different compute services based on the cloud platform:
- AWS: Amazon EC2 instances
- Azure: Azure Compute virtual machines
- GCP: Google Compute Engine instances
3. Cloud Services Layer
The cloud services layer is a central component of Snowflake’s architecture, acting as the “brain” of the system. It consists of a collection of services that coordinate activities across all aspects of Snowflake’s operations. These services are designed to tie together the various components of Snowflake to process user requests seamlessly, from initial login to query execution.
Services managed in this layer:
- Authentication and Access Control
- Infrastructure Management
- Metadata Management
- Query Optimization and Planning
- Transaction Management
- Security
While Snowflake’s compute layer employs a shared-nothing architecture within each virtual warehouse for query processing, the system uses a shared-data approach. This hybrid model allows Snowflake to offer the scalability and performance benefits of shared-nothing systems, while also providing the data sharing and elasticity advantages of shared-disk architectures. This architecture enables Snowflake to offer features like instant elasticity, high concurrency, and a simplified user experience, setting it apart from traditional data warehouse systems.
Key Advantages of Snowflake’s Architecture
- Elasticity: VWs can be created, destroyed, or resized at any point on demand.
- Concurrency: Multiple compute clusters can access the same data simultaneously.
- Performance:
- Local caching on SSDs for frequently accessed data
- Columnar storage and execution for analytical queries
- Micro-partitioning and metadata for efficient data pruning
- Simplicity: No need for manual data distribution or indexing.
- Cost-efficiency: Users only pay for storage and compute resources they actually use.
- Continuous availability: Online upgrades and fault tolerance at all levels.
- Data sharing: Easy to share data across different compute resources without copying.
Key Features of Snowflake
Elasticity of Compute Resources
Snowflake’s Virtual Warehouses provide exceptional elasticity:
- Users can create, destroy, or resize Virtual Warehouses on demand
- Scaling up or down has no effect on data storage
- Multiple Virtual Warehouses can be run concurrently, allowing for workload isolation
- This elasticity enables users to match compute resources precisely to their current needs
Isolation
- Each individual query runs on exactly one VW.
- Worker nodes are not shared across VWs, ensuring performance isolation.
Worker Processes
- When a new query is submitted, each worker node in the VW spawns a new worker process.
- This process lives only for the duration of its query.
Shared Data Access
- Every VW has access to the same shared tables without the need to physically copy data.
- This is a key benefit of Snowflake’s architecture, allowing data sharing across compute resources.
Local Caching
- Worker nodes maintain a cache of table data on local disk.
- The cache is a collection of table files (actually blob storage - S3 objects) accessed in the past by that node.
- It holds file headers and individual columns of files.
- The cache lives for the duration of the worker node and uses an LRU (Least Recently Used) replacement policy.
Query Optimization
To improve hit rates and avoid redundant caching across worker nodes, the query optimizer assigns input file sets to worker nodes using consistent hashing over table file names.
Snowflake incorporates several features to optimize query performance:
- Columnar storage and execution for efficient data access
- Vectorized execution to avoid materialization of intermediate results
- Push-based execution for improved cache efficiency
- Automatic pruning to limit data access to only relevant information
- Support for queries that spill to disk when memory is exhausted
File Stealing
- When a worker process completes scanning its set of input files, it can request additional files from its peers.
- This helps handle skew and balance load across nodes.
Execution Engine
- Snowflake uses its own state-of-the-art SQL execution engine.
- It is columnar, vectorized, and push-based, optimized for analytical queries.
Support for Semi-Structured Data
Snowflake extends standard SQL with support for semi-structured data:
- It introduces VARIANT, ARRAY, and OBJECT data types
- Users can load JSON, Avro, or XML data directly into VARIANT columns
- The system performs automatic type inference and optimistic conversions
- Semi-structured data is stored in a columnar format for efficient querying
- Performance on semi-structured data is nearly on par with relational data
Time Travel and Cloning
Snowflake offers powerful data recovery and reproduction features:
- Time Travel: Users can access historical data from any point within a configurable period (up to 90 days)
- Cloning: Tables, schemas, or entire databases can be cloned instantly without copying data
End-to-End Security
Security is a core design principle in Snowflake:
- All data is encrypted, both in transit and at rest
- It uses a hierarchical key model with automatic key rotation
- The system supports two-factor authentication and role-based access control
- Snowflake provides end-to-end encryption and security measures
Pure Software-as-a-Service Experience
Snowflake aims to simplify data warehousing:
- Users can interact with the system through a web interface, JDBC/ODBC, or various partner tools
- There are no tuning knobs, no need for physical design, and no storage grooming tasks
- The system automatically handles optimization, scaling, and most administrative tasks
SnowFlake Research Article
For those interested in a more technical deep-dive, I’ve attached the original Snowflake research paper below. While it’s a few years old now, it provides valuable insights into the foundational architecture and principles of Snowflake.