What is Microsoft Fabric
Explore Microsoft Fabric, an all-in-one analytics platform that simplifies data analytics for businesses and professionals. Discover its core features, including OneLake, and how it unifies various data tools, making data-driven decisions more accessible and cost-effective.


Microsoft Fabric: Revolutionizing Data Analytics
What is Microsoft Fabric?
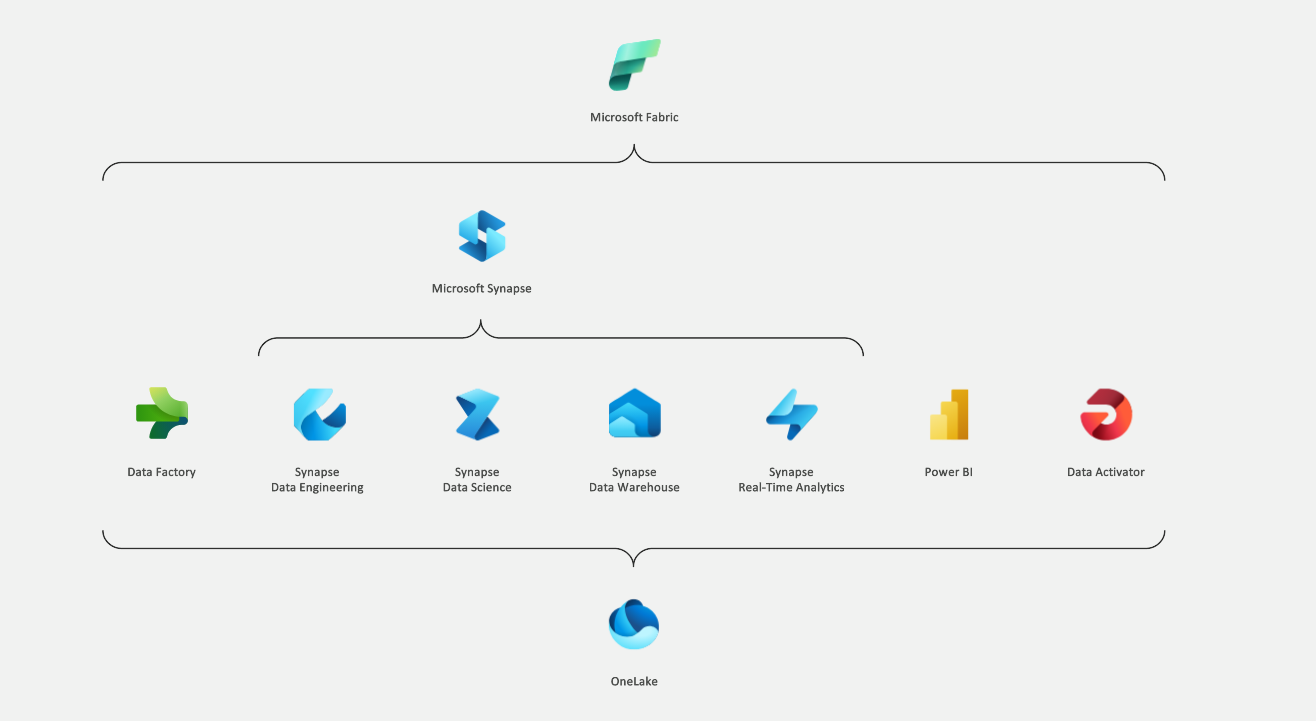
Microsoft Fabric is an end-to-end analytics and data platform designed for enterprises that require a unified solution. It encompasses data movement, processing, ingestion, transformation, real-time event routing, and report building. It offers a comprehensive suite of services including Data Engineering, Data Factory, Data Science, Real-Time Analytics, Data Warehouse, and Databases, and Business Intelligence.
In simple words, Microsoft Fabric is a comprehensive data and analytics platform designed to meet the diverse needs of modern enterprises. It offers a unified environment that integrates various data-related tasks, from data movement and processing to ingestion, transformation, real-time event routing, and report building. Fabric eliminates the need for organizations to piece together disparate services from multiple vendors, providing a seamless and user-friendly platform that simplifies analytics requirements.
The Purpose of Fabric: Simplicity
Fabric’s primary goal is simplicity. It allows organizations to integrate data from multiple sources into a single environment, enabling data professionals to concentrate on results rather than juggling between different technologies. This approach also streamlines licensing and interaction among different Azure tools like Synapse, Azure Data Factory, and Power BI.
Microosft Fabric Key Components and Features:
-
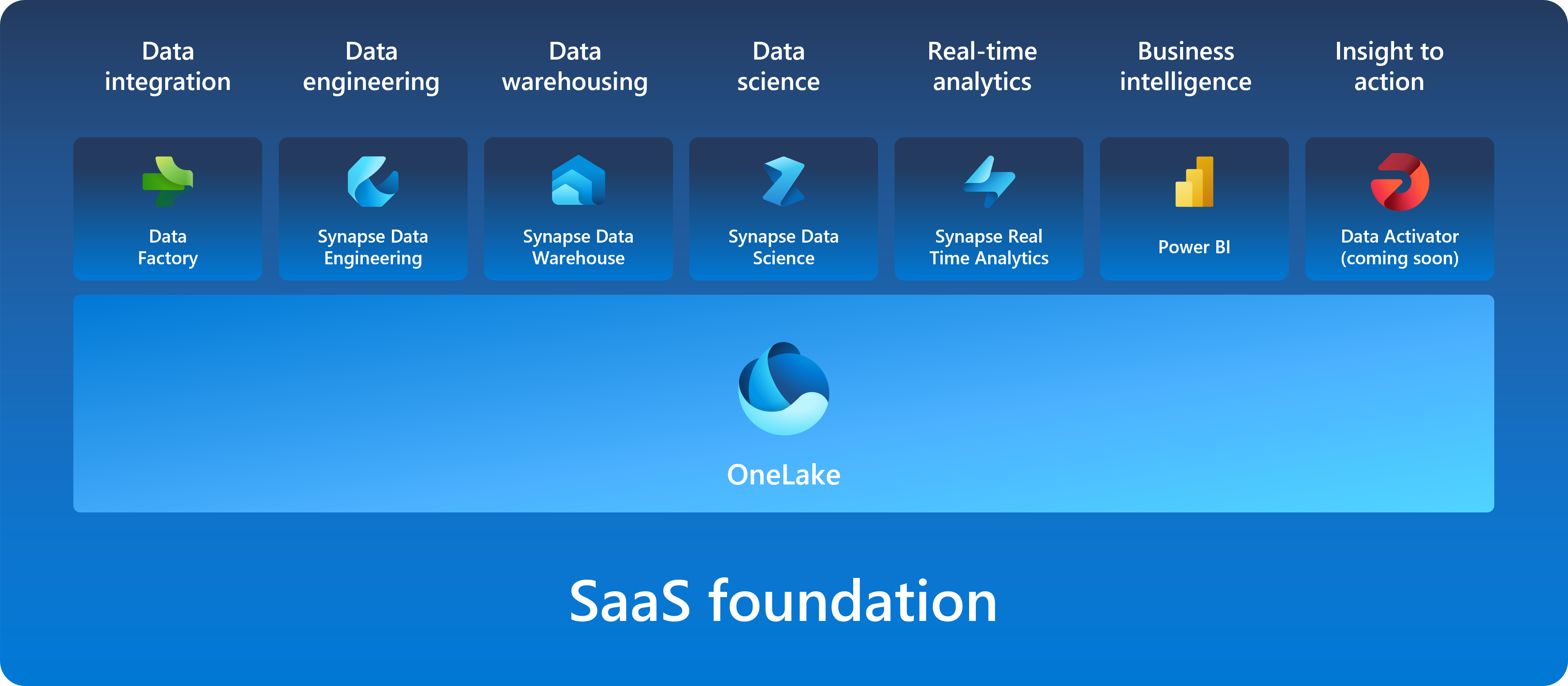
Unified SaaS Foundation: Fabric is built on a Software as a Service (SaaS) model, integrating both new and existing components from Power BI, Azure Synapse Analytics, Azure Data Factory, and other services into a cohesive environment. Integrated Workloads: Fabric brings together various workloads, including Data Engineering, Data Factory, Data Science, Data Warehouse, Real-Time Intelligence, Industry solutions, and Power BI, into a shared SaaS foundation. Each workload is tailored for specific user roles and tasks, ensuring a seamless experience for data engineers, scientists, and warehousing professionals.
-
OneLake Data Hub: Fabric’s OneLake data hub serves as a centralized repository for all organizational data. It eliminates data silos and simplifies data discovery, sharing, and governance. OneLake is built on Azure Data Lake Storage Gen2 and provides a single SaaS experience for both professional and citizen developers.
-
Real-Time Hub: The Real-Time hub is a foundational component for managing data in motion. It provides a unified view of all real-time data streams from various sources, enabling users to discover, ingest, manage, and consume data in motion for streaming applications.
-
AI Integration: Fabric seamlessly integrates AI capabilities throughout the platform, accelerating the data journey and enabling users to derive actionable insights from raw data.
-
Comprehensive Analytics Experiences: Fabric offers a wide range of analytics experiences tailored to specific personas and tasks. These experiences include Power BI for data visualization and reporting, Data Factory for data integration, Data Activator for real-time data monitoring and actions, Industry Solutions for industry-specific needs, Real-Time Intelligence for event-driven scenarios, and Synapse Data Engineering, Data Science, and Data Warehouse for advanced data processing and analysis.
-
Cost Reduction Through Unified Capacities: Fabric reduces resource wastage by allowing the purchase of a single compute pool for all workloads, significantly reducing costs and resource management complexity.
OneLake:
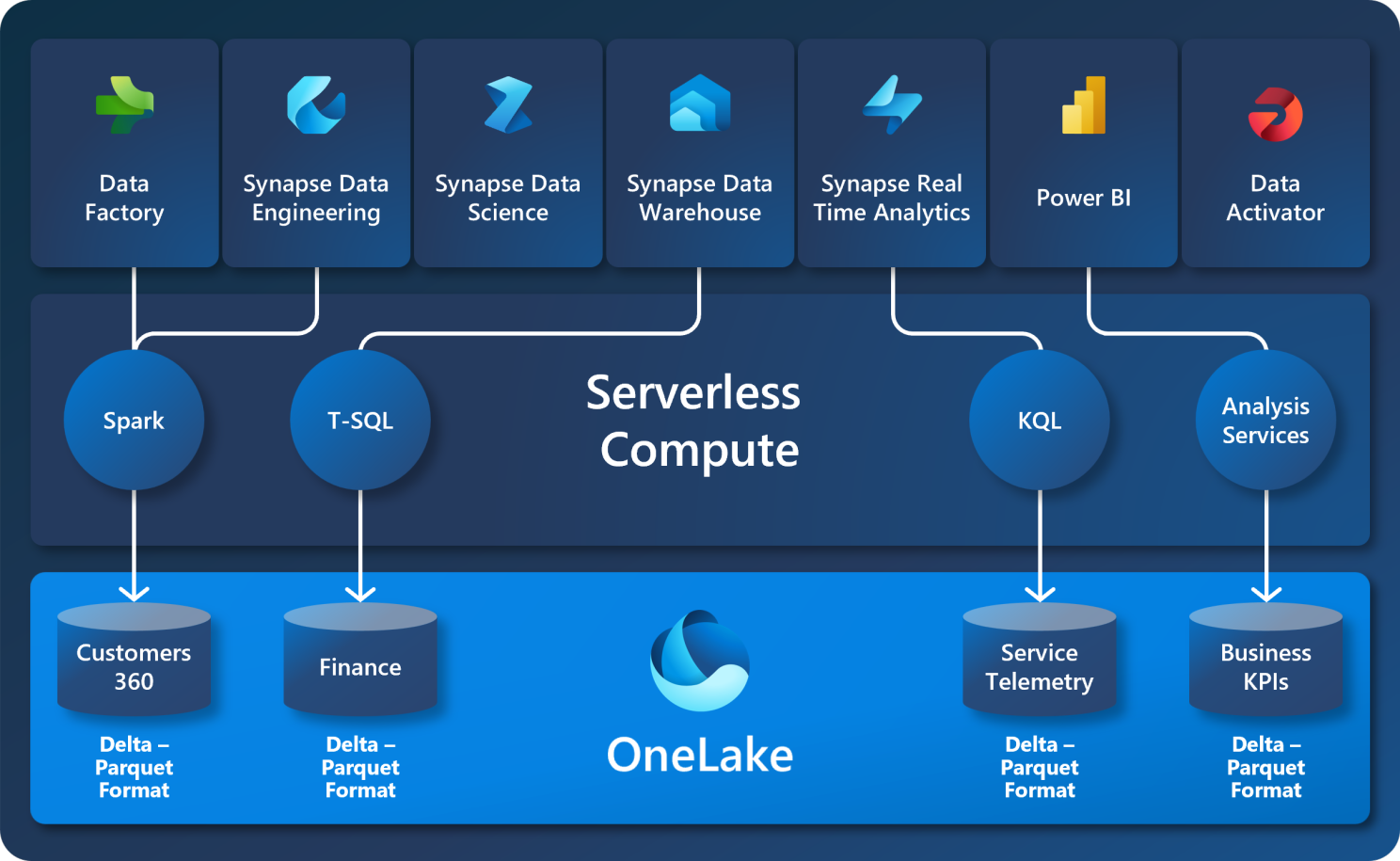
OneLake is Microsoft Fabric’s built-in data lake and the central data repository of Fabric, designed to be the single, unified storage system for all your organization’s data. It’s built on Azure Data Lake Storage Gen2 and offers a seamless Software as a Service (SaaS) experience, eliminating the need for users to grapple with complex infrastructure concepts. It is a unified, logical data lake that supports all Fabric workloads. It’s comparable to OneDrive in its functionality but for data. OneLake breaks down data silos, enhancing collaboration and simplifying organizational data management.
Why OneLake is Important
-
Eliminates Data Silos: OneLake breaks down data silos that often arise when developers create isolated storage accounts. By providing a unified storage system, it ensures easy data discovery, sharing, and consistent enforcement of policies and security.
-
Simplifies Data Management: OneLake abstracts away infrastructure complexities, allowing users to focus on data analysis and collaboration rather than managing resources. In Microsoft Fabric there is no need to create any storage accounts in azure (like ADLSGen2) and assign them, the storage is auto provised in the background.
-
Hierarchical Structure: OneLake organizes data into a hierarchical structure with the tenant at the root, followed by workspaces (folders), and then lakehouses (collections of files, folders, and tables). This structure simplifies data management and allows developers and business units to create their own workspaces for collaboration.
-
Streamlines Fabric Experiences: All Microsoft Fabric compute experiences are pre-wired to OneLake, making it the native store for data engineering, data warehousing, data factory, Power BI, and real-time intelligence.
-
Integrates with Existing Storage: OneLake’s Shortcut feature allows you to mount existing Platform as a Service (PaaS) storage accounts, providing access to data stored in Azure Data Lake Storage without migration.
-
Enables Cross-Cloud Collaboration: Shortcuts also enable easy data sharing between users and applications across different clouds, reducing egress costs and bringing data closer to compute resources.
Microosoft Fabric Terminology:
To navigate the Fabric landscape, it’s essential to understand its key terms:
-
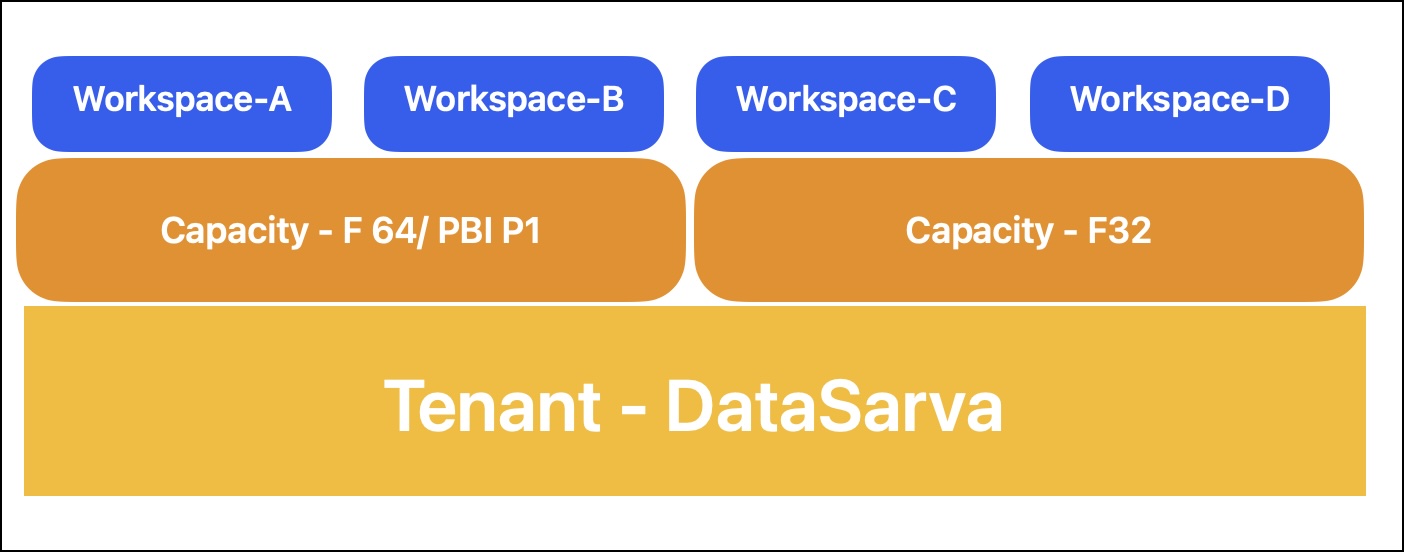
Tenant: Think of this as your organization’s dedicated Fabric space, linked to your Microsoft Entra ID (formerly Azure Active Directory). It’s the top-level container for all your Fabric assets.
-
Capacity: This is the engine that powers your Fabric experience. It’s a set of resources that determines how much you can do and how fast you can do it. Fabric offers different capacity options, including trials and paid SKUs, to suit your needs. You can have multiple capacity licences, but the tenant will be one for the entire organization/domain.
-
Workspace: Imagine this as a collaborative project folder within your tenant. It’s where you and your team create, edit, and organize your Fabric items, using the allocated capacity. You can assign one capacity license to the multiple workspaces.
-
Item: This is the building block of your Fabric projects. It could be a report, a dataset, a notebook, or any other asset you create within a specific Fabric experience.
-
Experience: This is a collection of capabilities designed for a particular function. For instance, the “Data Engineering” experience offers tools for building data pipelines, while the “Power BI” experience focuses on data visualization and reporting.
-
Lakehouse: This is a special type of item within the Data Engineering experience. It’s like a database built on top of your data lake (OneLake), allowing you to organize and analyze large volumes of structured and unstructured data.
Let’s have a look at Different Persona in Microsoft Fabric:
1. Data Factory
Overview: The Data Factory in Microsoft Fabric is a critical component for data integration.
-
Connectors: Tools that enable connections to various data stores for ingestion and transformation.
-
Data Pipeline: A workflow for orchestrating data movement and transformation.
-
Dataflow Gen2: A low-code interface for ingesting and transforming data from diverse sources.
-
Trigger: An automation capability that initiates pipelines based on specific conditions.
Key Features:
- Provides more than 150 connectors to both cloud and on-premise data sources.
- Offers drag-and-drop experiences for easy data transformation.
- Enables efficient orchestration of data pipelines, facilitating seamless data flow between various sources and destinations.
2. Synapse Data Engineering
Overview: This workload focuses on enhancing data engineering capabilities within Fabric.
-
Lakehouse: A collection of files, folders, and tables representing a database over a data lake, used for big data processing with ACID transactions.
-
Notebook: A multi-language interactive programming tool for authoring code, running Spark jobs, visualizing results, and collaborating.
-
Spark Application: A user-written program using Spark’s API languages or Microsoft-added languages for data processing.
-
Apache Spark Job: A parallel unit of execution within a Spark application.
-
Apache Spark Job Definition: Parameters defining how a Spark application should run.
-
V-order: A write optimization for Parquet files enabling faster reads and better performance.
Key Features:
- Offers Lakehouse architecture, enabling a blend of data lake and data warehouse capabilities.
- Supports great authoring experiences using the Spark engine, which is known for its speed and ease of use.
- Features like instant start with live pools and collaboration tools streamline the data engineering process.
3. Synapse Data Warehouse
Overview: The Data Warehouse workload provides advanced data warehousing solutions.
-
SQL Analytics Endpoint: Allows querying Delta table data with T-SQL over TDS.
-
Synapse Data Warehouse: A traditional data warehouse supporting full transactional T-SQL capabilities.
Key Features:
- Delivers a unified, serverless, and dedicated SQL engine, optimized for open data formats.
- Offers a converged experience of a lakehouse and data warehouse, providing flexibility and scalability.
- Enables data engineers and analysts to manage and analyze large data sets efficiently.
4. Synapse Data Science
Overview: Designed for data scientists, this workload supports the end-to-end data science process.
-
Data Wrangler: A notebook-based tool for immersive exploratory data analysis and cleansing.
-
Experiment: The primary unit for organizing and controlling related machine learning runs.
-
Model: A file trained to recognize patterns and make predictions.
-
Run: A single execution of model code.
Key Features:
- Provides a comprehensive set of tools for building sophisticated AI models.
- Enables collaboration on projects and offers functionalities to train, deploy, and manage machine learning models.
- Supports a wide array of data science activities, from data preparation to model deployment.
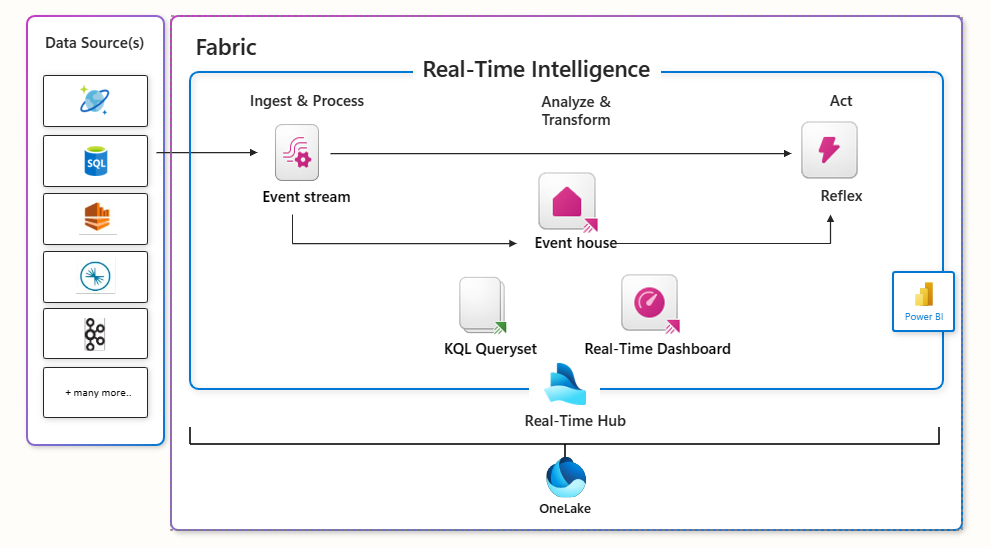
5. Synapse Real-Time Analytics
Overview: This workload is tailored for processing and analyzing real-time data streams.
-
KQL Database: Stores data in a format suitable for executing KQL queries.
-
KQL Queryset: An item for running, viewing, and manipulating KQL query results on data from a Data Explorer database.
-
Event Stream: A centralized feature for capturing, transforming, and routing real-time events.
Key Features:
- Ideal for handling data from IoT devices, telemetry, logs, and more.
- Employs Kusto Query Language (KQL) for high-performance analysis of semi-structured data.
- Facilitates low-latency operations, crucial for real-time data applications.
6. Business Intelligence (Power BI)
-
Overview: At the core of Fabric’s business intelligence workload is Power BI.
-
Key Features:
- Offers AI-driven analytics and industry-leading data visualization capabilities.
- Deeply integrated with Microsoft 365, enhancing productivity and insights discovery within familiar applications.
- Enables business analysts and users to derive meaningful insights from organizational data.
7. Data Activator
Overview: A unique, no-code interface within Microsoft Fabric focused on automating data-driven actions, such as email notifications and Power Automate workflows, to launch when Data Activator detects specific patterns or conditions in your changing data.
- Reflex: Reflex is a destination for streaming data in the Real-Time Intelligence hub. It allows for real-time actions to be taken on data, such as sending email notifications or triggering Power Automate workflows.
Key Features:
- Designed to trigger actions based on identified patterns or specific conditions in evolving data.
- Empowers users to create and manage automated workflows without the need for coding.
- Enhances efficiency by autonomously initiating responses to data changes.
Each of these workloads represents a facet of Microsoft Fabric’s comprehensive approach to data management and analytics, offering tailored solutions for different aspects of the data lifecycle. This modular yet integrated approach ensures that whether you’re managing data pipelines, engaging in complex data science projects, or seeking insights through business intelligence, Microsoft Fabric has a dedicated toolset to support your endeavors.
Additional Considerations
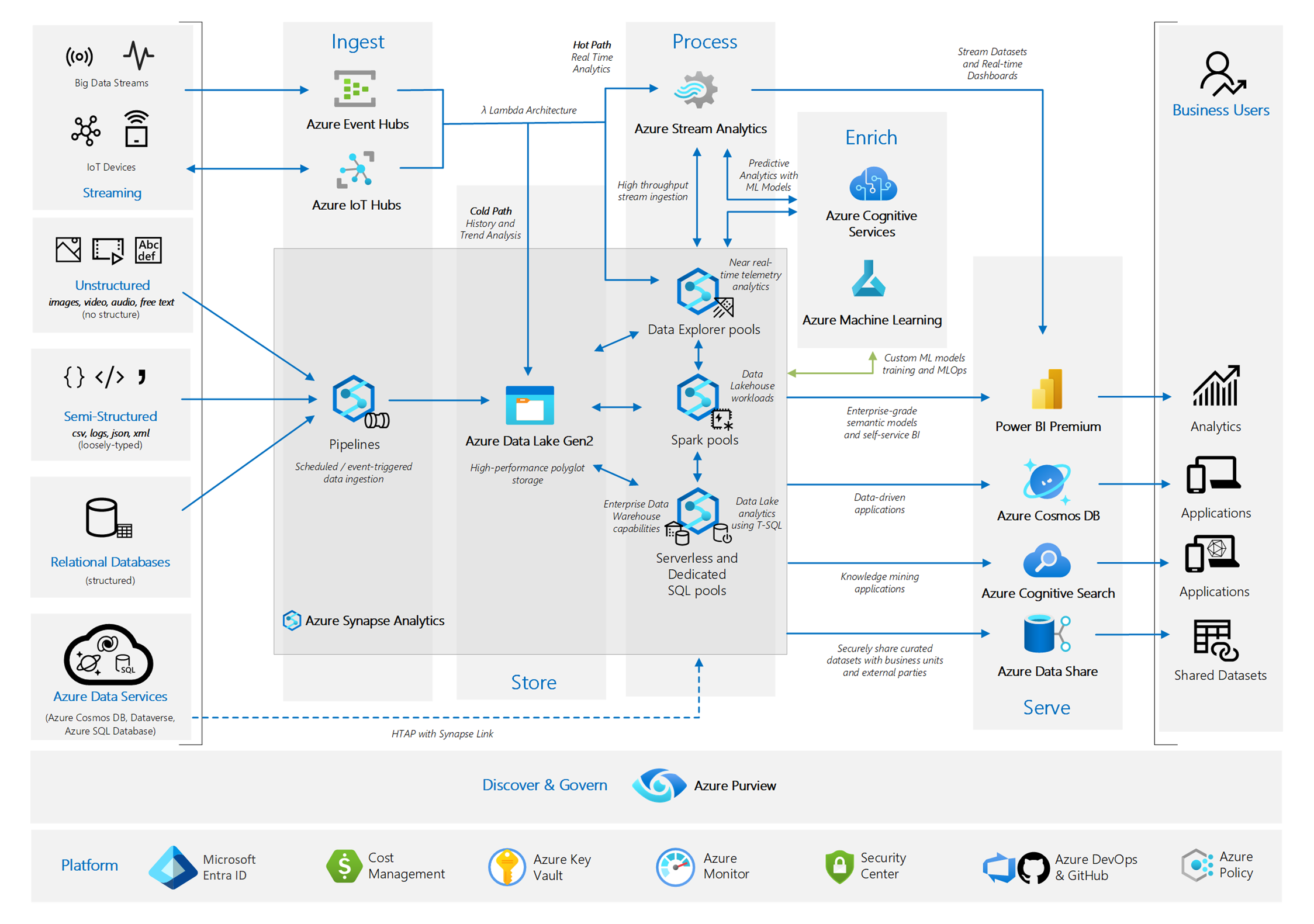
- Data Mesh Architecture: Fabric is an implementation of data mesh architecture, enabling organizations to manage large and complex data repositories effectively.
Microsoft Fabric Data Mesh Architecture Implementation Guide
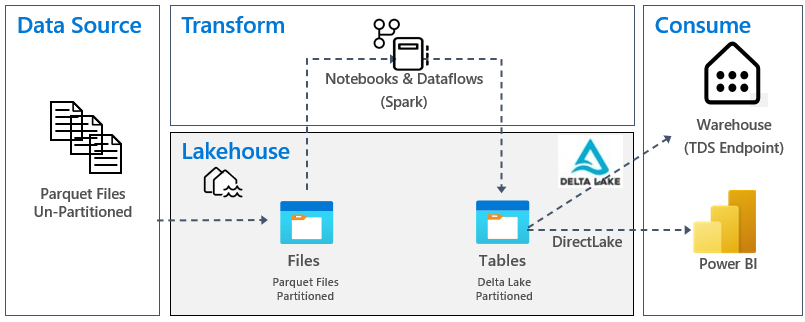
- Lakehouse Architecture: The platform unifies OneLake and lakehouse architecture across the enterprise, providing a scalable and flexible solution for data storage and processing.
Microsoft Fabric Data Lakehouse Architecture Implementation Guide
- Real-Time Intelligence: Fabric’s Real-Time Intelligence capabilities enable organizations to extract insights, visualize, and act on data in motion, supporting event-driven scenarios and real-time analytics.
Microsoft Fabric Real-Time Intelligence Implementation Guide
- ISV Integration: Fabric offers various integration paths for Independent Software Vendors (ISVs) to integrate their solutions with the platform, ranging from basic interoperability to building custom workloads and experiences.
Conclusion
Microsoft Fabric is a groundbreaking platform that unifies a variety of Azure tools and services. It is a comprehensive and integrated platform designed to empower users across various roles and skill levels in the data and analytics domain. It seamlessly combines data engineering, data science, data warehousing, and real-time intelligence capabilities into a unified SaaS foundation. By leveraging the OneLake data hub, Fabric eliminates data silos and simplifies data management, providing a centralized repository for all organizational data.
Data engineers can leverage Fabric’s Spark-based data processing capabilities and lakehouse architecture to build scalable and efficient data pipelines. Data scientists can seamlessly integrate their machine learning models with Fabric, enriching organizational data with predictions for better decision-making. Data analysts can utilize tools like Data Wrangler and Power BI to explore, clean, transform, visualize, and share data insights.