Delta Lake tables in Microsoft Fabric
This article explores the integration of Delta Lake tables within Microsoft Fabric's lakehouse architecture. It highlights the key features of Delta Lake, including relational table operations, ACID transactions, data versioning, and support for batch and streaming data. Readers will gain insights into the benefits of combining relational databases with data lakes and practical steps for managing delta tables in Apache Spark for data analysis.


Delta Lake tables in Microsoft Fabric
Microsoft Fabric lakehouse tables leverage the Delta Lake table format, a key component in Apache Spark. Delta Lake, an open-source storage layer, introduces relational database functions to both batch and streaming data in Spark. This integration forms a lakehouse architecture, allowing SQL-based operations, transaction support, and schema enforcement in Spark. Essentially, it combines the benefits of relational databases with the flexibility of data lakes. While direct interaction with Delta Lake APIs isn’t mandatory for using Fabric lakehouse tables, understanding Delta Lake’s metastore architecture and its unique table operations is beneficial for developing sophisticated analytics solutions on Microsoft Fabric.
Delta Lake
Delta Lake is an innovative open-source storage layer that enhances data lakes with relational database capabilities. It’s a key component of Microsoft Fabric’s lakehouse architecture, where Delta tables are easily identified by a Delta (▴) icon.
These tables are essentially schema structures over data files stored in the Delta format, including Parquet data files and a _delta_log folder for transaction logs in JSON.
Key features of Delta Lake include:
-
Relational Table Operations: Compatible with Apache Spark, Delta Lake allows for CRUD operations, enabling users to perform standard database actions like selecting, inserting, updating, and deleting data.
-
ACID Transactions: Delta Lake supports atomic, consistent, isolated, and durable transactions, similar to relational databases. This ensures reliable and secure data modifications.
-
Data Versioning and Time Travel: Every transaction is logged, allowing for multiple versions of data and the ability to access previous versions through time travel queries.
-
Support for Batch and Streaming Data: Delta Lake tables work with both static and streaming data, integrating with Spark’s Structured Streaming API for versatile data handling.
-
Standard Formats and Interoperability: The data is stored in the widely-used Parquet format, ensuring compatibility across various data ingestion pipelines. Delta tables can also be queried using SQL analytics endpoints in Microsoft Fabric’s lakehouse.
Delta tables play a crucial role in managing and storing data within Microsoft Fabric’s lakehouse architecture. They are essentially a bridge between the table definitions in the metastore and the actual Parquet files storing the data. Here’s a simpler breakdown of how to create and manage delta tables, especially when working with Apache Spark.
Hands-On:
-
Begin by launching your workspace and setting up a new Lakehouse, naming it as you prefer. Once your lakehouse is ready, you’ll need to populate it with data for analysis.
-
Start by downloading the required data file, ‘products.csv’, from the provided GitHub link - products.csv. Save it to your local machine or a lab virtual machine, if you’re using one.
Next, go back to your lakehouse in the web browser. Here’s how to upload your data:
- Navigate to the Explorer pane and find the Files folder.
- Create a new subfolder within it, named ‘products’.
- Use the Upload option in the products folder menu to select and upload the ‘products.csv’ file from your device.
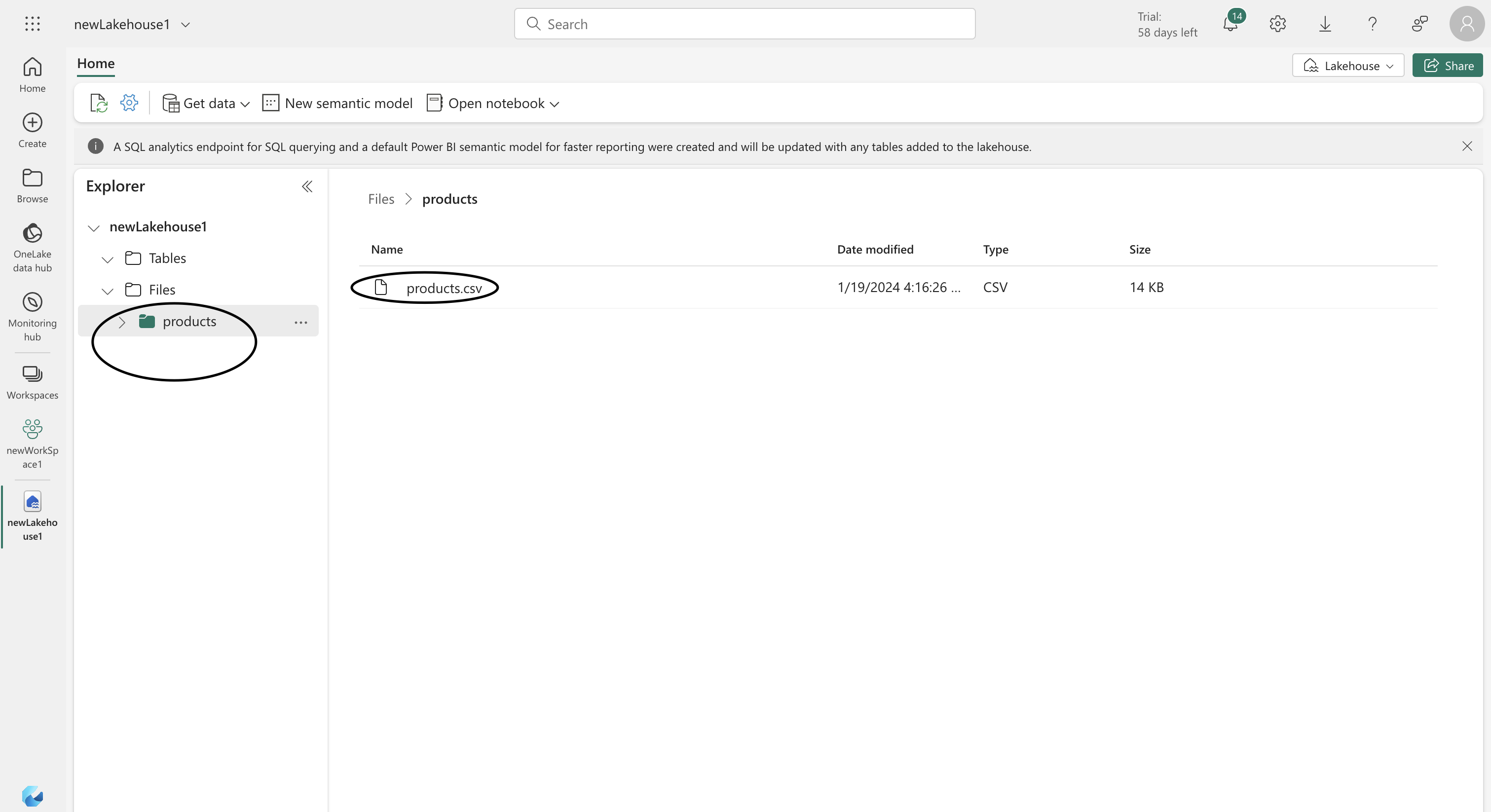
Next, start by opening a new notebook from the Open notebook menu on the Home page of your datalake. Once the notebook is open, delete the pre-existing code cell using the 🗑 icon. Then, navigate to the Lakehouse explorer pane, expand the Files section, and select the ‘products’ folder to access the ‘products.csv’ file you previously uploaded. This will set up your environment for data analysis.
df = spark.read.format("csv").option("header","true").load("Files/products/products.csv")
# df now is a Spark DataFrame containing CSV data from "Files/products/products.csv".
display(df.limit(5))StatementMeta(, d37f27ac-42a0-422e-80b8-88097bb98770, 30, Finished, Available)
| ID | Product | Category | Price |
| --- | ------------------------- | -------------- | -------- |
| 771 | Mountain-100 Silver, 38 | Mountain Bikes | 3399.9900|
| 772 | Mountain-100 Silver, 42 | Mountain Bikes | 3399.9900|
| 773 | Mountain-100 Silver, 44 | Mountain Bikes | 3399.9900|
| 774 | Mountain-100 Silver, 48 | Mountain Bikes | 3399.9900|
| 775 | Mountain-100 Black, 38 | Mountain Bikes | 3374.9900|
Creating a Delta Table from a DataFrame:
- You can easily create a delta table in Spark by saving a DataFrame in delta format.
- This process saves the data in Parquet files and creates a _delta_log folder for transaction logs. The table appears in the Data explorer pane.
df.write.format("delta").saveAsTable("managed_products")StatementMeta(, d37f27ac-42a0-422e-80b8-88097bb98770, 9, Finished, Available)
df.write.format("delta").saveAsTable("external_products", path="abfss://newWorkSpace1@onelake.dfs.fabric.microsoft.com/newLakehouse1.Lakehouse/Files/external_products")StatementMeta(, d37f27ac-42a0-422e-80b8-88097bb98770, 10, Finished, Available)
Managed vs External Tables:
- Managed Table: The Spark runtime manages both the table definition and the underlying data files. Deleting the table also removes the files. External Table: The table definition in the metastore is linked to an external file storage location. Deleting the table does not affect the data files.
%%sql
DESCRIBE FORMATTED managed_products;StatementMeta(, d37f27ac-42a0-422e-80b8-88097bb98770, 11, Finished, Available)
| col_name | data_type| comment |
| ----------------------- | -------- | ----------------------------------------------------------------------------------------- |
| ProductID | string | NULL |
| ProductName | string | NULL |
| Category | string | NULL |
| ListPrice | string | NULL |
| | | |
| # Detailed Table Information | | |
| Name | | spark_catalog.newlakehouse1.managed_products |
| Type | | MANAGED |
| Location | | abfss://ff2c582d-a64b-4e99-81b6-.... |
| Provider | | delta |
| Owner | | trusted-service-user |
| Table Properties | | [delta.minReaderVersion=1,delta.minWriterVersion=2] |
%%sql
DESCRIBE FORMATTED external_products;StatementMeta(, d37f27ac-42a0-422e-80b8-88097bb98770, 12, Finished, Available)
| col_name | data_type| comment |
| ----------------------- | -------- | ----------------------------------------------------------------------------------------- |
| ProductID | string | NULL |
| ProductName | string | NULL |
| Category | string | NULL |
| ListPrice | string | NULL |
| | | |
| # Detailed Table Information | | |
| Name | | spark_catalog.newlakehouse1.managed_products |
| Type | | EXTERNAL |
| Location | | abfss://newWorkSpace1@onelake.dfs.fabric.microsoft.... |
| Provider | | delta |
| Owner | | trusted-service-user |
| Table Properties | | [delta.minReaderVersion=1,delta.minWriterVersion=2] |
%%sql
DROP TABLE managed_products;
DROP TABLE external_products;StatementMeta(, , -1, Finished, Available)
<Spark SQL result set with 0 rows and 0 fields>
<Spark SQL result set with 0 rows and 0 fields>
Using Spark SQL:
- This is a common method to interact with Delta tables. You can perform SQL operations by embedding SQL statements in other programming languages like PySpark or Scala using the spark.sql library. For instance, you can insert or update data in a table using simple SQL commands.
%%sql
CREATE TABLE products
USING DELTA
LOCATION 'Files/external_products';StatementMeta(, d37f27ac-42a0-422e-80b8-88097bb98770, 15, Finished, Available)
<Spark SQL result set with 0 rows and 0 fields>
%%sql
SELECT * FROM products LIMIT 5;StatementMeta(, d37f27ac-42a0-422e-80b8-88097bb98770, 22, Finished, Available)
| ID | Product | Category | Price |
| --- | ------------------------- | -------------- | -------- |
| 771 | Mountain-100 Silver, 38 | Mountain Bikes | 3059.991 |
| 772 | Mountain-100 Silver, 42 | Mountain Bikes | 3059.991 |
| 773 | Mountain-100 Silver, 44 | Mountain Bikes | 3059.991 |
| 774 | Mountain-100 Silver, 48 | Mountain Bikes | 3059.991 |
| 775 | Mountain-100 Black, 38 | Mountain Bikes | 3037.491 |
Explore table versioning
Transaction history for delta tables is stored in JSON files in the delta_log folder. You can use this transaction log to manage data versioning.
%%sql
UPDATE products
SET ListPrice = ListPrice * 0.9
WHERE Category = 'Mountain Bikes';StatementMeta(, d37f27ac-42a0-422e-80b8-88097bb98770, 17, Finished, Available)
<Spark SQL result set with 1 rows and 1 fields>
Time Travel with Table Versioning: Delta tables log all modifications, allowing you to view the history of changes and retrieve previous versions of the data. You can use the DESCRIBE HISTORY command to see the table’s transaction log, and use options like versionAsOf or timestampAsOf to access specific versions of the data.
%%sql
DESCRIBE HISTORY products;StatementMeta(, d37f27ac-42a0-422e-80b8-88097bb98770, 18, Finished, Available)
| Index | Timestamp | userID | userName | operation | operationParameters | job | notebook | readVersion |
|---|--------------------------|--------------------|--------------------------------------------------|-----------------|--------------|--------------|----------------------------------------------------------------------------------------------------------------------|--------------------------------------------------|
| 1 | 2024-01-19T22:49:46Z | NULL | NULL | UPDATE | Serializable | false | {"predicate":["(Category#1996 = Mountain Bikes)"]} | Apache-Spark/3.4.1.5.3-110807746 Delta-Lake/2.4.0.8 |
| 0 | 2024-01-19T22:39:04Z | NULL | NULL | CREATE TABLE AS SELECT | Serializable | true | {"isManaged":"false","description":null,"partitionBy":"[]","properties":"{}"} | Apache-Spark/3.4.1.5.3-110807746 Delta-Lake/2.4.0.8 |
delta_table_path = 'Files/external_products'
# Get the current data
current_data = spark.read.format("delta").load(delta_table_path)
display(current_data.limit(5))
# Get the version 0 data
original_data = spark.read.format("delta").option("versionAsOf", 0).load(delta_table_path)
display(original_data.limit(5))StatementMeta(, d37f27ac-42a0-422e-80b8-88097bb98770, 21, Finished, Available)
| ID | Product | Category | Price |
| --- | ------------------------- | -------------- | -------- |
| 771 | Mountain-100 Silver, 38 | Mountain Bikes | 3059.991 |
| 772 | Mountain-100 Silver, 42 | Mountain Bikes | 3059.991 |
| 773 | Mountain-100 Silver, 44 | Mountain Bikes | 3059.991 |
| 774 | Mountain-100 Silver, 48 | Mountain Bikes | 3059.991 |
| 775 | Mountain-100 Black, 38 | Mountain Bikes | 3037.491 |
| ID | Product | Category | Price |
| --- | ------------------------- | -------------- | -------- |
| 771 | Mountain-100 Silver, 38 | Mountain Bikes | 3399.9900|
| 772 | Mountain-100 Silver, 42 | Mountain Bikes | 3399.9900|
| 773 | Mountain-100 Silver, 44 | Mountain Bikes | 3399.9900|
| 774 | Mountain-100 Silver, 48 | Mountain Bikes | 3399.9900|
| 775 | Mountain-100 Black, 38 | Mountain Bikes | 3374.9900|
Streamlining Data Analysis with Delta Tables and Spark Structured Streaming
In the fast-evolving field of data analytics, processing streaming data in real-time is crucial, particularly with the increasing use of Internet-of-Things (IoT) devices. Apache Spark’s Structured Streaming feature provides a comprehensive solution for this, offering continuous data ingestion, processing, and output.
Key Features of Spark Structured Streaming
- Versatile Data Sources: Capable of reading from a variety of sources including network ports, messaging services like Azure Event Hubs or Kafka, and file systems.
- Real-time Dataframe Operations: Utilizes a boundless dataframe for real-time data manipulation and processing.
Integrating Delta Tables with Spark Structured Streaming
Delta tables can be used as a source or a sink in Spark Structured Streaming workflows.
As a Streaming Source
- Stores data such as internet sales orders in delta tables.
- Enables real-time streaming of newly appended data.
- Note: Suitable for append operations. Modifications or deletions need specific options like
ignoreChangesorignoreDeletes.
As a Streaming Sink
- Streams data, like JSON-formatted IoT device statuses, into delta tables.
- Important to use
checkpointLocationfor state tracking and failure recovery.
Practical Applications
- Processes data in various ways, like aggregating over time windows for real-time analytics.
- Streamed data can be queried from the delta table for current insights.
- Use the
stopmethod on the streaming query to end the data stream.
Conclusion
Using delta tables with Spark Structured Streaming greatly simplifies real-time data processing. This combination is essential for scenarios needing rapid data ingestion and processing. For more details, refer to the Spark and Delta Lake documentation.
from notebookutils import mssparkutils
from pyspark.sql.types import *
from pyspark.sql.functions import *
# Create a folder
inputPath = 'Files/data/'
mssparkutils.fs.mkdirs(inputPath)
# Create a stream that reads data from the folder, using a JSON schema
jsonSchema = StructType([
StructField("device", StringType(), False),
StructField("status", StringType(), False)
])
iotstream = spark.readStream.schema(jsonSchema).option("maxFilesPerTrigger", 1).json(inputPath)
# Write some event data to the folder
device_data = '''{"device":"Dev1","status":"ok"}
{"device":"Dev1","status":"ok"}
{"device":"Dev1","status":"ok"}
{"device":"Dev2","status":"error"}
{"device":"Dev1","status":"ok"}
{"device":"Dev1","status":"error"}
{"device":"Dev2","status":"ok"}
{"device":"Dev2","status":"error"}
{"device":"Dev1","status":"ok"}'''
mssparkutils.fs.put(inputPath + "data.txt", device_data, True)
print("Source stream created...")StatementMeta(, d37f27ac-42a0-422e-80b8-88097bb98770, 23, Finished, Available)
Source stream created...
# Write the stream to a delta table
delta_stream_table_path = 'Tables/iotdevicedata'
checkpointpath = 'Files/delta/checkpoint'
deltastream = iotstream.writeStream.format("delta").option("checkpointLocation", checkpointpath).start(delta_stream_table_path)
print("Streaming to delta sink...")StatementMeta(, d37f27ac-42a0-422e-80b8-88097bb98770, 24, Finished, Available)
Streaming to delta sink...
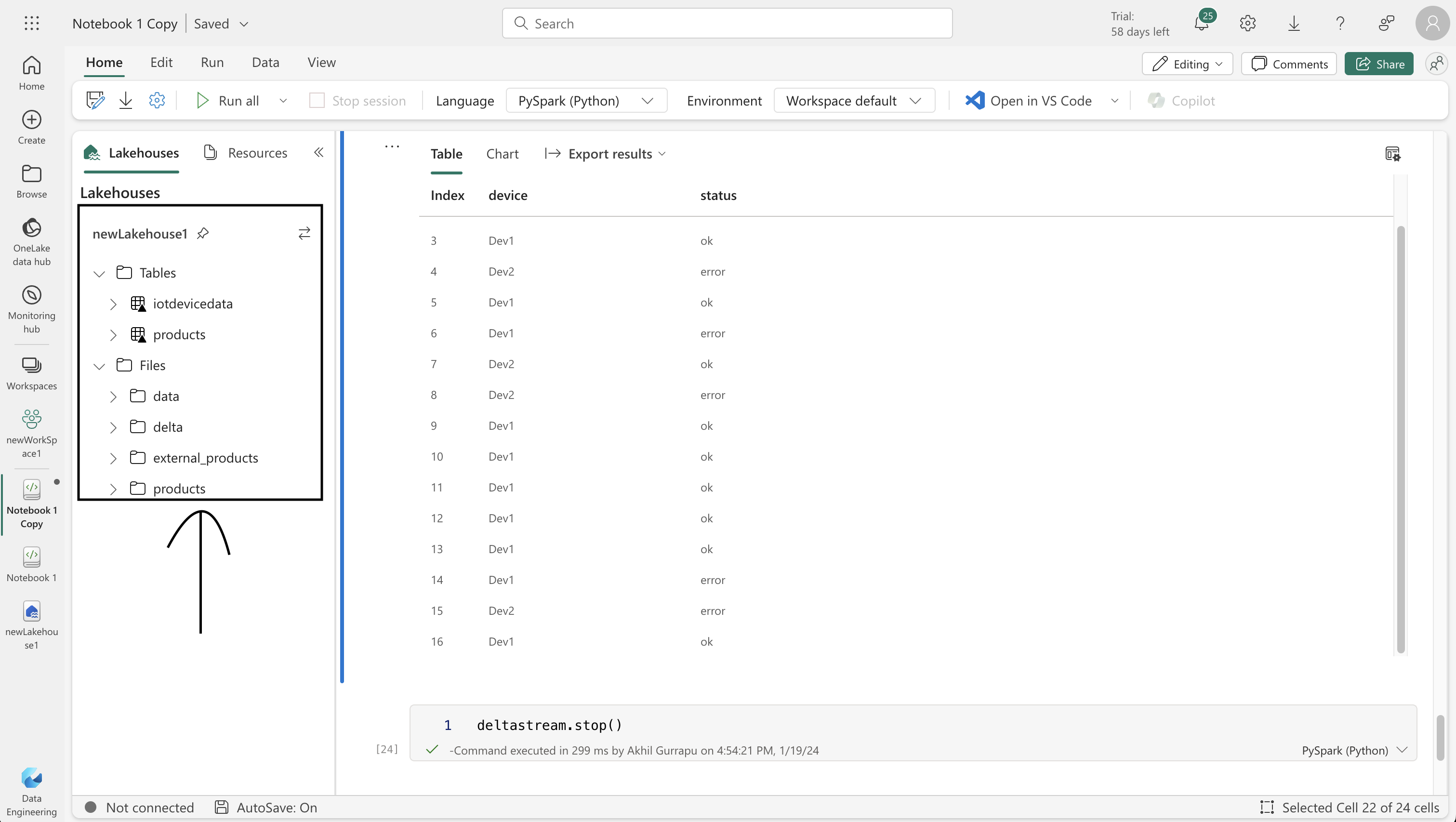
%%sql
SELECT * FROM IotDeviceData;StatementMeta(, d37f27ac-42a0-422e-80b8-88097bb98770, 25, Finished, Available)
| devic | Status |
| --------- | ------ |
| Dev1 | ok |
| Dev1 | ok |
| Dev1 | ok |
| Dev2 | error |
| Dev1 | ok |
| Dev1 | error |
| Dev2 | ok |
| Dev2 | error |
| Dev1 | ok |
# Add more data to the source stream
more_data = '''{"device":"Dev1","status":"ok"}
{"device":"Dev1","status":"ok"}
{"device":"Dev1","status":"ok"}
{"device":"Dev1","status":"ok"}
{"device":"Dev1","status":"error"}
{"device":"Dev2","status":"error"}
{"device":"Dev1","status":"ok"}'''
mssparkutils.fs.put(inputPath + "more-data.txt", more_data, True)StatementMeta(, d37f27ac-42a0-422e-80b8-88097bb98770, 27, Finished, Available)
True
%%sql
SELECT * FROM IotDeviceData;StatementMeta(, d37f27ac-42a0-422e-80b8-88097bb98770, 28, Finished, Available)
| device | Status |
| --------- | ------ |
| Dev1 | ok |
| Dev1 | ok |
| Dev1 | ok |
| Dev2 | error |
| Dev1 | ok |
| Dev1 | error |
| Dev2 | ok |
| Dev2 | error |
| Dev1 | ok |
| Dev1 | ok |
| Dev1 | ok |
| Dev1 | ok |
| Dev1 | ok |
| Dev1 | error |
| Dev2 | error |
| Dev1 | ok |
deltastream.stop()StatementMeta(, d37f27ac-42a0-422e-80b8-88097bb98770, 29, Finished, Available)