Data Integration in Microsoft Fabric Data Warehouse
Uncover the power of Microsoft Fabric Data Warehouse. Learn its key features, ETL process, and data loading strategies. Explore data pipelines, advanced SQL capabilities, and Dataflow Gen2. Get hands-on with workspace setup, lakehouse creation, and data analysis. Master data integration with Microsoft Fabric.

Data Integration in Microsoft Fabric Data Warehouse
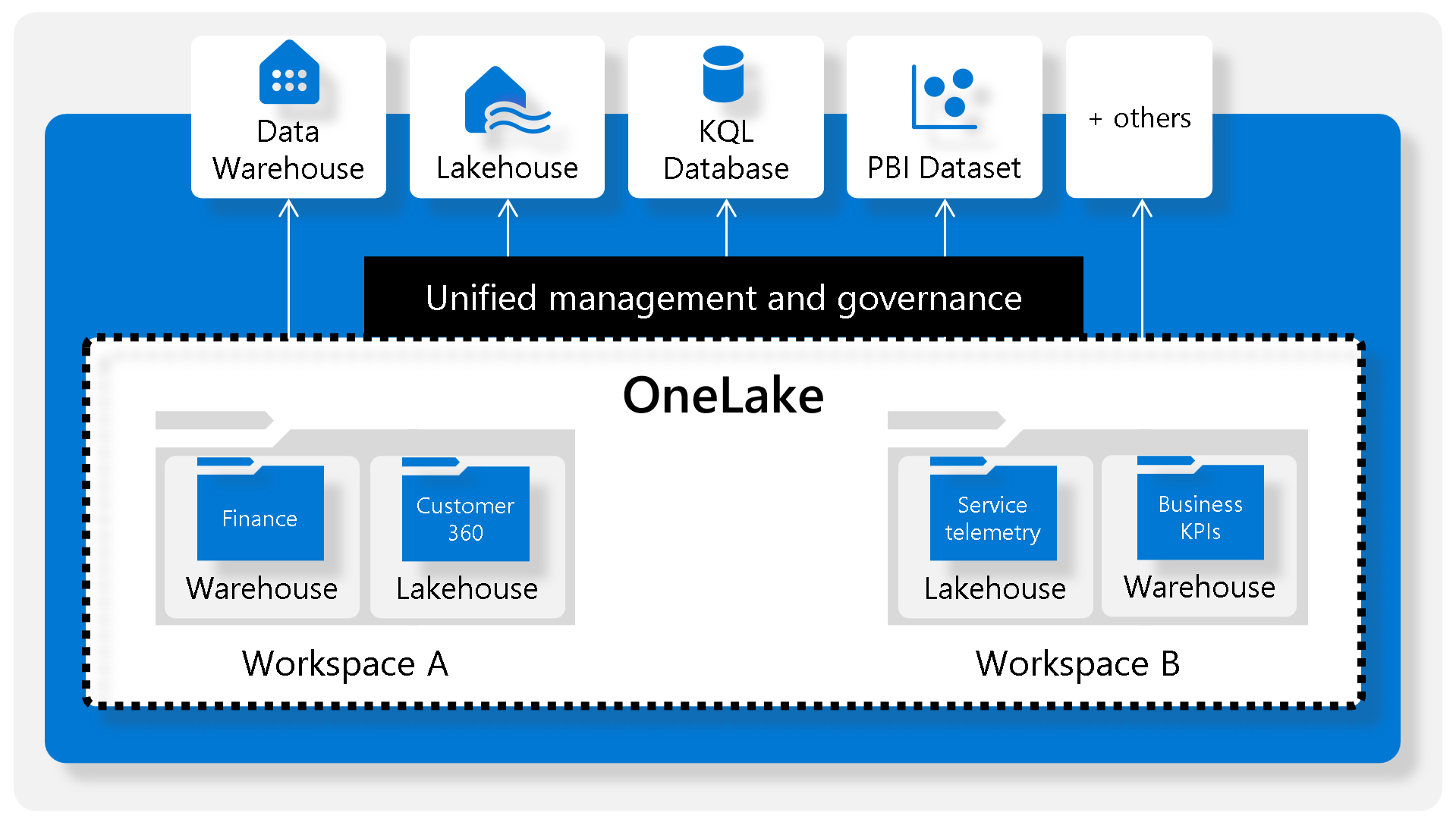
Microsoft Fabric Data Warehouse is a comprehensive solution for data storage, organization, and analysis, enhanced by its integration with Synapse Analytics. It simplifies managing vast amounts of structured and semi-structured data, offering advanced querying capabilities and full T-SQL support.
Key Features:
- Synapse Analytics Integration: Empowers the data warehouse with advanced query processing and transactional capabilities.
- Centralized Data Lake: Focuses on a single data lake, storing data in Parquet format in Microsoft OneLake, streamlining data preparation, analysis, and reporting.
- Utilization of SQL Engine: Leverages SQL engine’s extensive capabilities for efficient data management.
ETL Process Overview:
- Data Extraction: Involves connecting to source systems to gather necessary data.
- Data Transformation: Converts extracted data into a standard format, including data cleaning, deduplication, and validation.
- Data Loading: Involves loading data into the warehouse, either fully or incrementally, to ensure compatibility with the warehouse schema.
- Post-load Optimizations: Enhances data warehouse performance after data loading.
Data Load Strategies in Microsoft Fabric
Introduction
Data loading in Microsoft Fabric is a crucial step in integrating high-quality, transformed data into a single repository. Its efficiency is key for accurate analytics and real-time decision-making. Understanding the different aspects of data loading, from ingestion to the final load, is essential for a successful data warehouse project.
-
Data Ingestion vs. Data Load Operations
- Data Ingestion/Extract: Moves raw data from various sources into a central repository.
- Data Loading: Involves transferring processed data into the final storage for analysis and reporting.
-
Staging Your Data
- Staging objects, like tables and functions, act as temporary areas for data storage and transformation.
- They provide a buffer to minimize load operation impacts on data warehouse performance.
-
Types of Data Loads
- Full (Initial) Load: Populates the warehouse for the first time; involves complete data refresh.
- Incremental Load: Updates the warehouse with new changes; more complex but quicker than a full load.
-
Loading Dimension Tables
- Dimension tables provide context to raw data in fact tables, detailing the “who, what, where, when, why”.
-
Understanding Slowly Changing Dimensions (SCD)
- SCDs track changes in data over time. Types include:
- Type 0: Unchanging attributes.
- Type 1: Overwrites existing data without history.
- Type 2: Keeps full history; adds new records for changes.
- Type 3: Adds history as a new column.
- Type 4: Introduces a new dimension.
- Type 5: For large dimensions where Type 2 isn’t feasible.
- Type 6: A combination of Types 2 and 3.
- SCDs track changes in data over time. Types include:
-
Loading Fact Tables
- Involves transferring transaction data, like sales, from OLTP systems to the data warehouse.
- Uses JOIN operations to map keys from dimension tables to the fact table.
Data Integration in Microsoft Fabric Data Warehouse: A Guide to Data Pipelines, SQL, and Dataflow Gen2
Utilizing Data Pipelines in Microsoft Fabric:
-
Creating a Data Pipeline:
- Microsoft Fabric’s Warehouse integrates with Azure Data Factory for seamless data pipeline creation. Users can start from the workspace by selecting “New” and then “Data pipeline,” or directly from the warehouse asset.
-
Configuring Data Pipelines:
- There are three main options: adding pipeline activity, copying data, and choosing from predefined templates. The Copy Data Assistant simplifies data transfer with an easy-to-use interface.
-
Scheduling:
- Pipelines can be scheduled from the pipeline editor, allowing for regular data updates and transformations.
SQL Capabilities for Data Management:
-
The COPY Statement:
- Central to SQL in Microsoft Fabric, it allows efficient data import from Azure storage, supporting formats like PARQUET and CSV.
-
Advanced SQL Features:
- Users can execute complex queries, handle errors, and load multiple files. Features like CREATE TABLE AS SELECT and INSERT…SELECT facilitate data handling across different warehouse assets.
Dataflow Gen2 – The New Power Query Experience:
-
Creating and Importing Dataflows:
- Easily accessible from the workspace, Dataflow Gen2 streamlines the process of data import and transformation.
-
Data Transformation with Copilot:
- An innovative feature that assists in transforming data based on user inputs.
-
Setting a Data Destination:
- Users can define where the transformed data should be stored, such as in a warehouse, lakehouse, or Azure SQL Database.
-
Publishing the Dataflow:
- Once the dataflow is finalized, publishing it makes the transformations active and ready for use.
Hands-on:
-
Workspace Creation:
- Start by setting up a workspace in Microsoft Fabric, ensuring you have a trial or higher version of Microsoft Office 365.
-
Lakehouse Creation and Data Upload:
- Create a new lakehouse in the Synapse Data Engineering home page.
- Upload this file to your lakehouse.
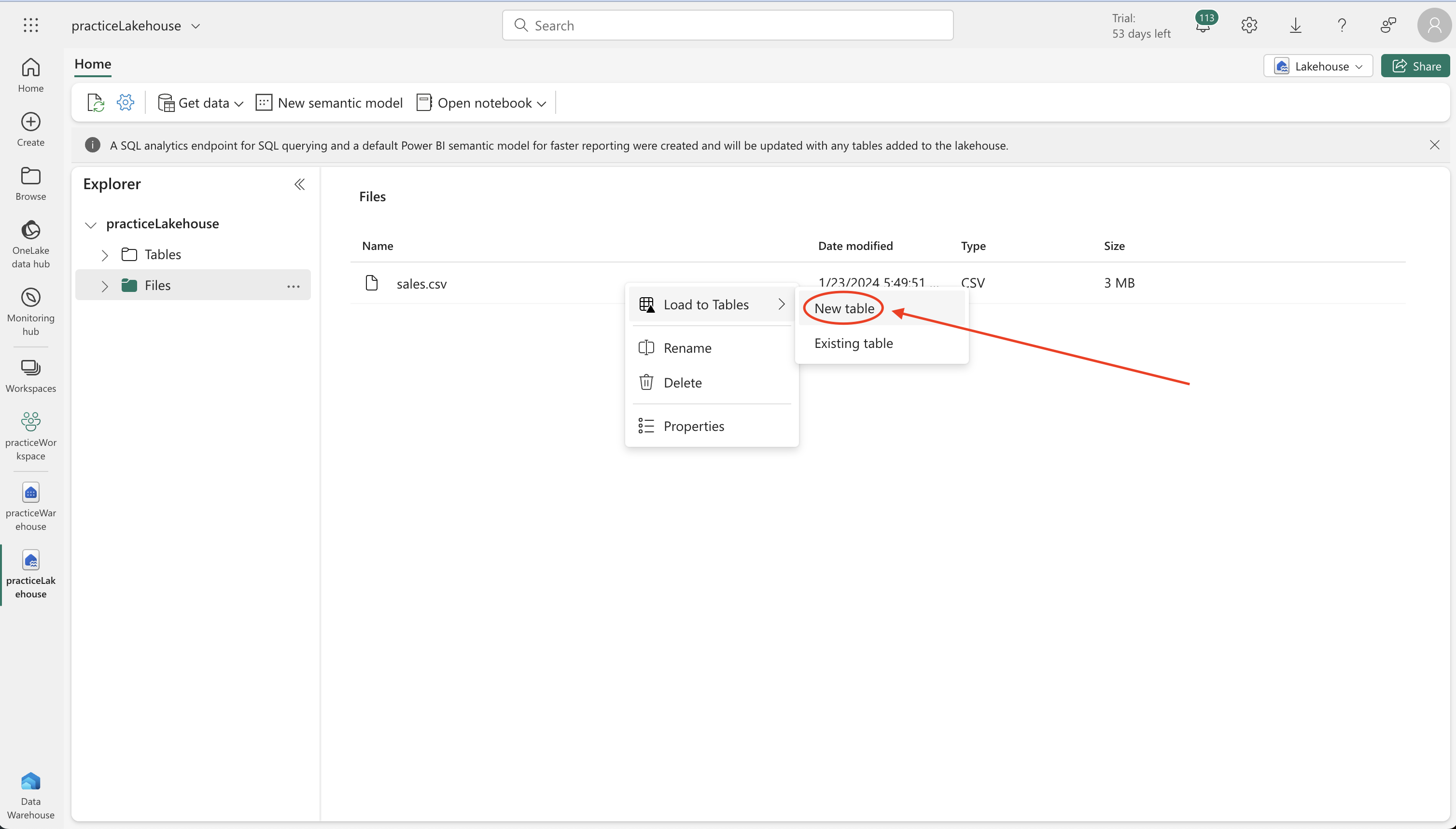
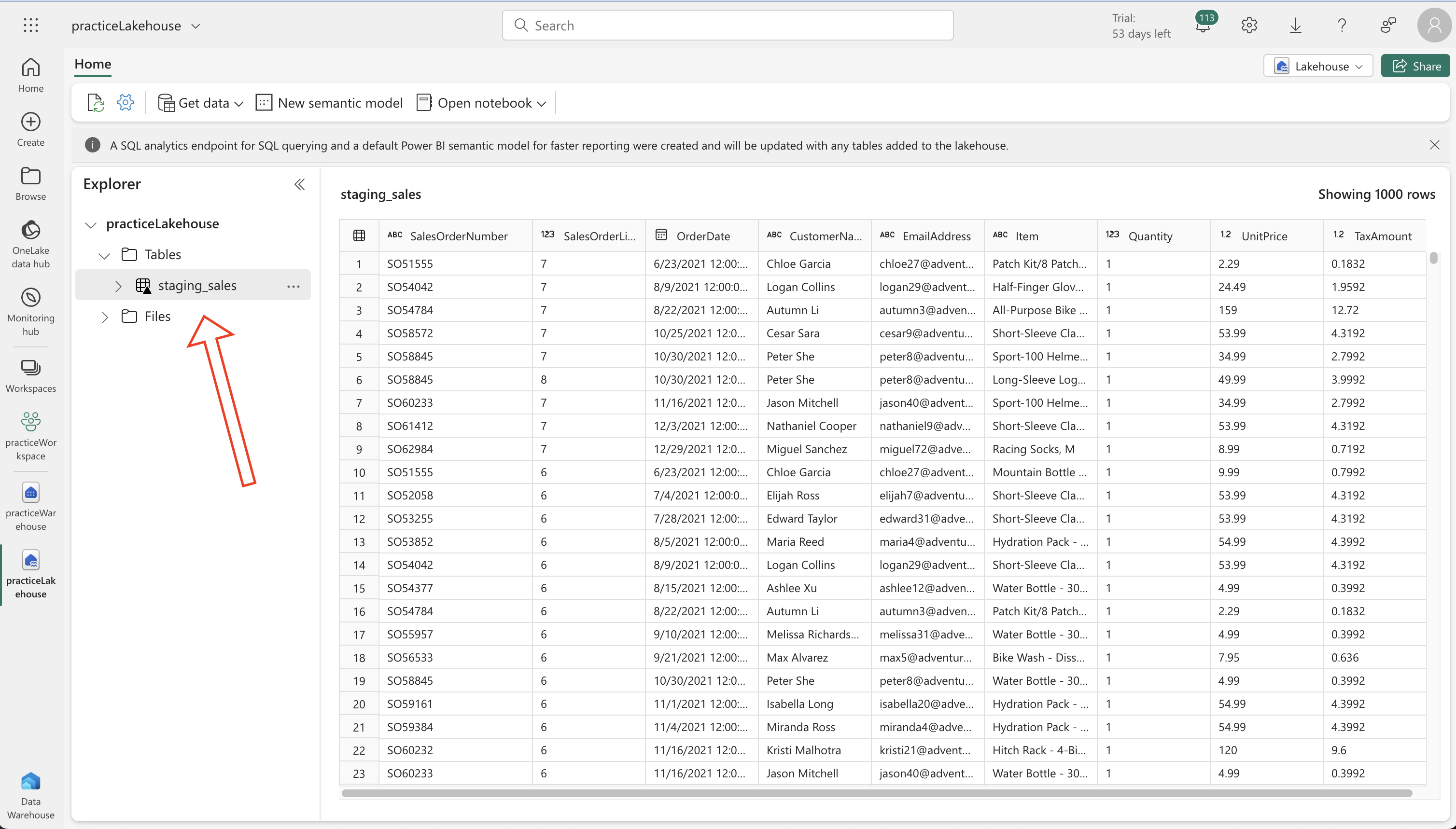
- Lakehouse Table Setup:
- Use the option ‘Load to tables’ for the sales.csv file to create a new table named staging_sales.
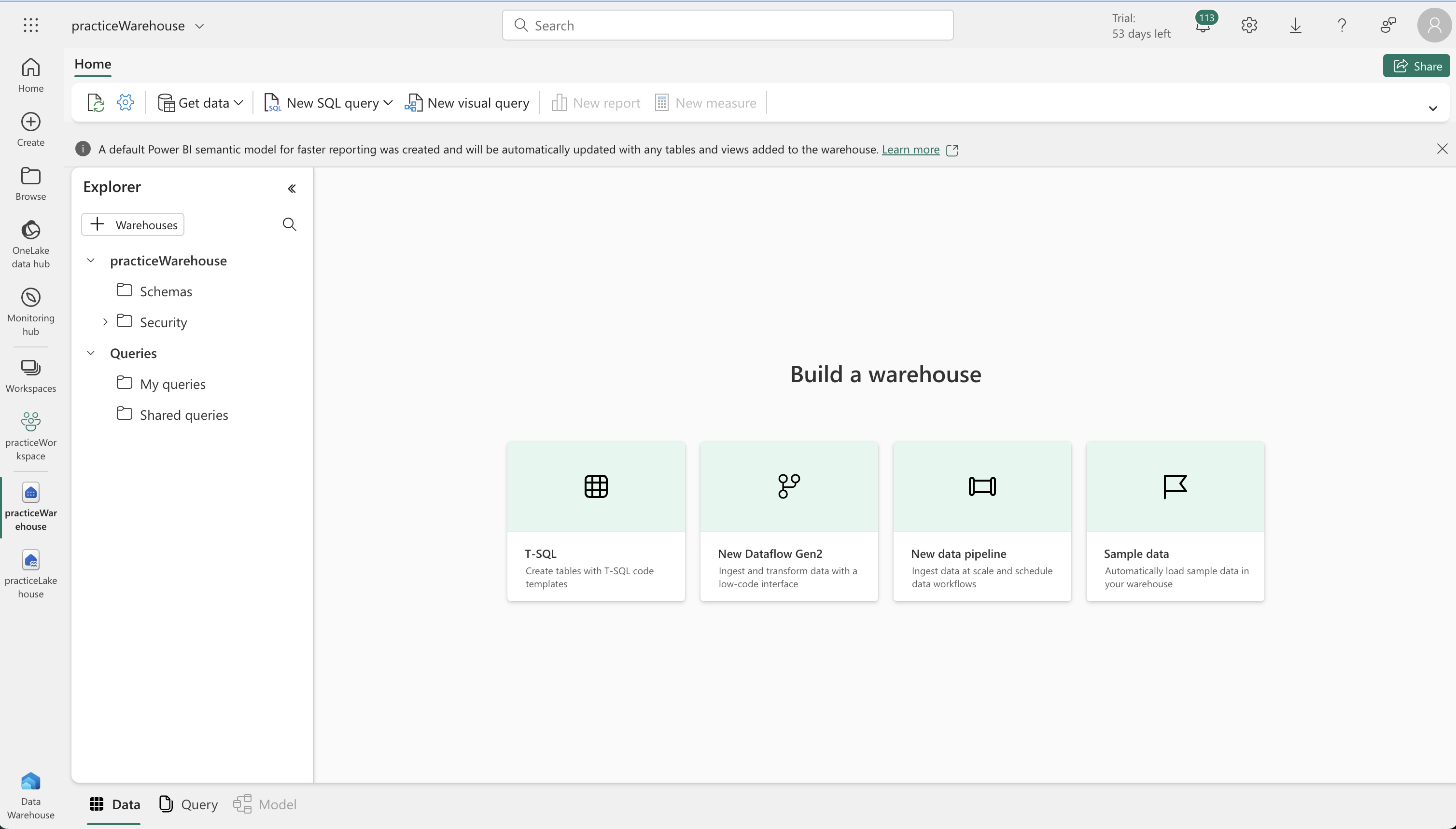
- Warehouse Creation:
- In the Synapse Data Warehouse home page, create a new data warehouse.
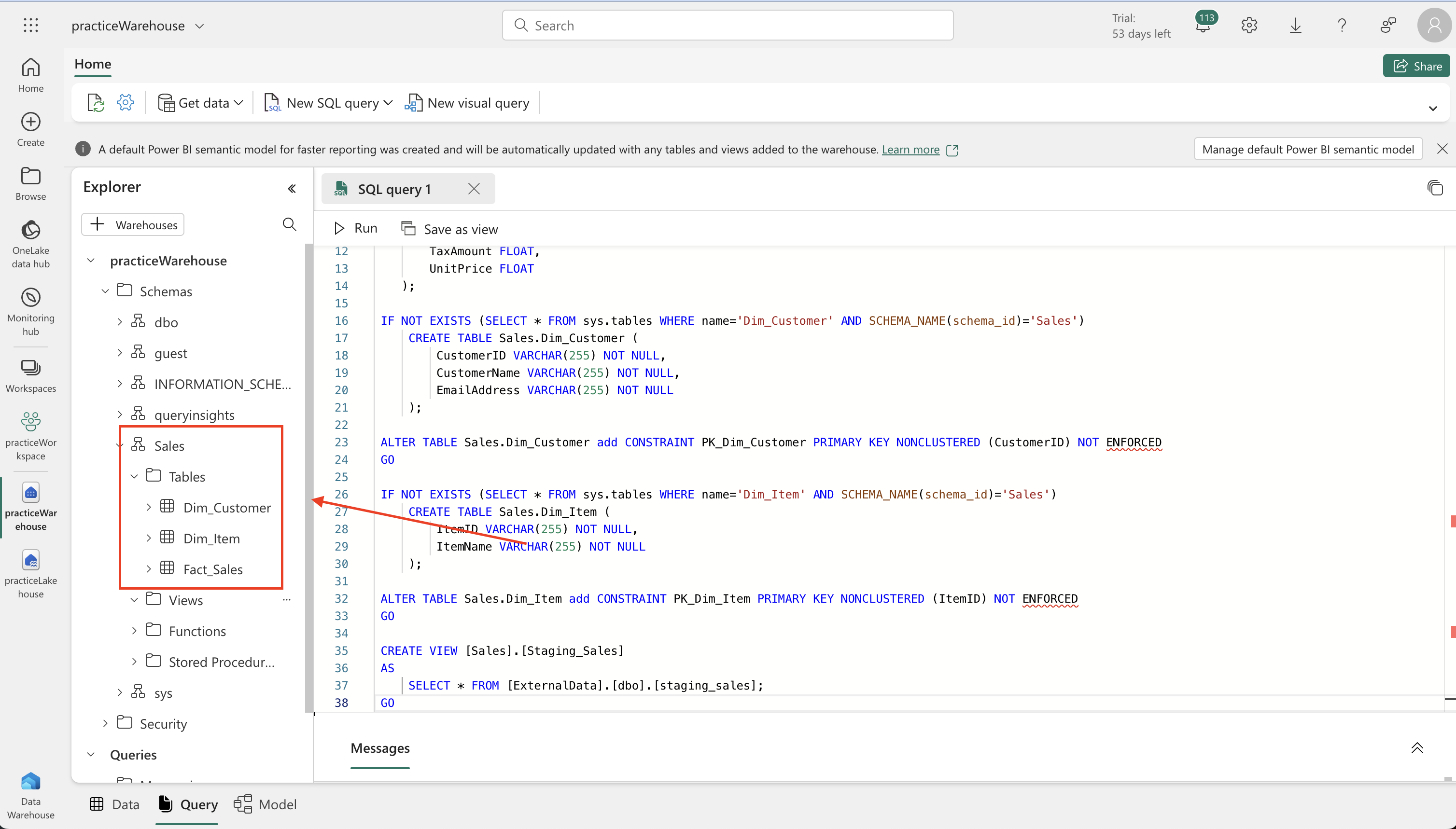
- Database Schema and Table Creation:
CREATE SCHEMA [Sales]
GO
IF NOT EXISTS (SELECT * FROM sys.tables WHERE name='Fact_Sales' AND SCHEMA_NAME(schema_id)='Sales')
CREATE TABLE Sales.Fact_Sales (
CustomerID VARCHAR(255) NOT NULL,
ItemID VARCHAR(255) NOT NULL,
SalesOrderNumber VARCHAR(30),
SalesOrderLineNumber INT,
OrderDate DATE,
Quantity INT,
TaxAmount FLOAT,
UnitPrice FLOAT
);
IF NOT EXISTS (SELECT * FROM sys.tables WHERE name='Dim_Customer' AND SCHEMA_NAME(schema_id)='Sales')
CREATE TABLE Sales.Dim_Customer (
CustomerID VARCHAR(255) NOT NULL,
CustomerName VARCHAR(255) NOT NULL,
EmailAddress VARCHAR(255) NOT NULL
);
ALTER TABLE Sales.Dim_Customer add CONSTRAINT PK_Dim_Customer PRIMARY KEY NONCLUSTERED (CustomerID) NOT ENFORCED
GO
IF NOT EXISTS (SELECT * FROM sys.tables WHERE name='Dim_Item' AND SCHEMA_NAME(schema_id)='Sales')
CREATE TABLE Sales.Dim_Item (
ItemID VARCHAR(255) NOT NULL,
ItemName VARCHAR(255) NOT NULL
);
ALTER TABLE Sales.Dim_Item add CONSTRAINT PK_Dim_Item PRIMARY KEY NONCLUSTERED (ItemID) NOT ENFORCED
GO
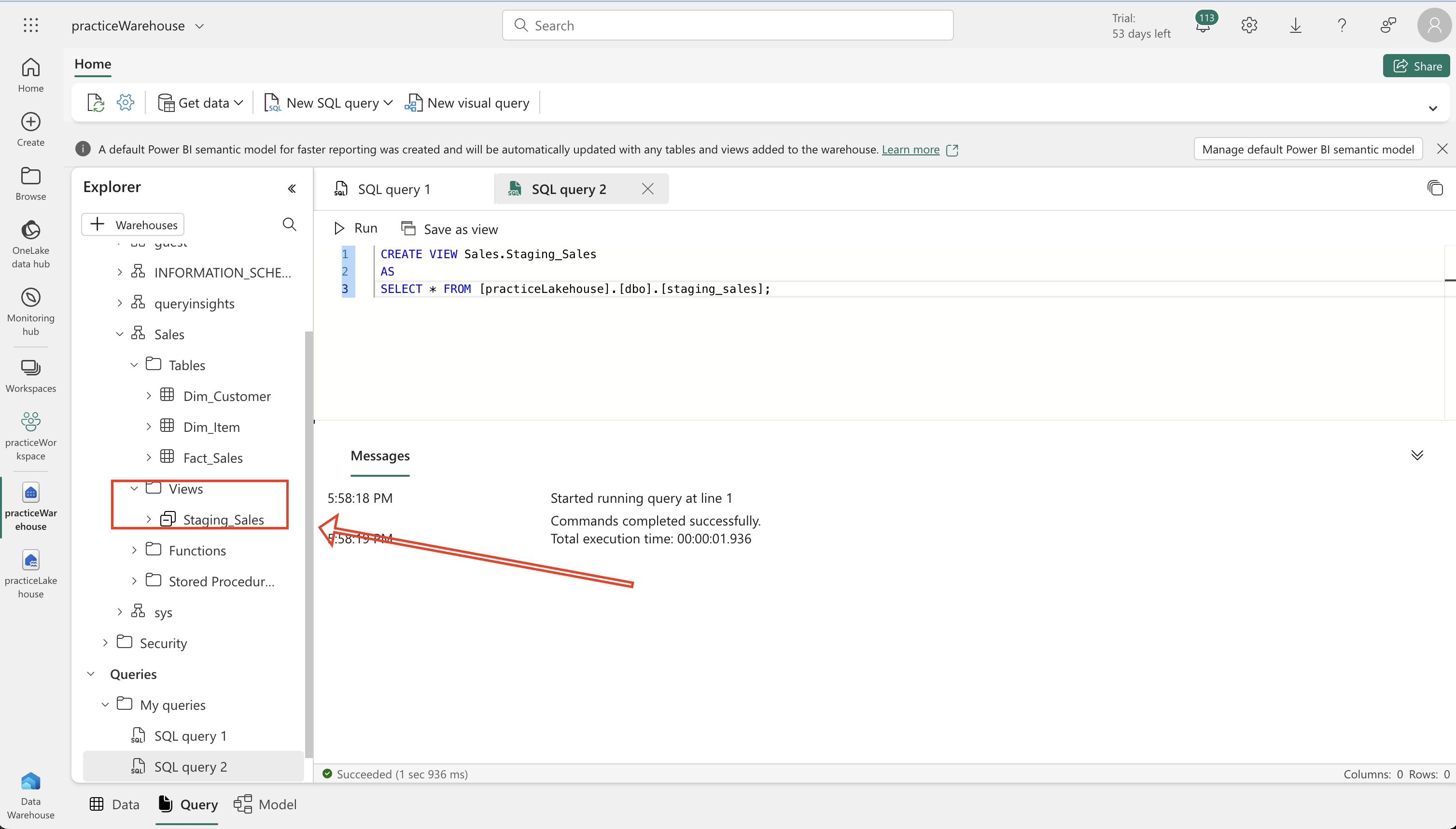
CREATE VIEW [Sales].[Staging_Sales]
AS
SELECT * FROM [ExternalData].[dbo].[staging_sales];
GO- Define a schema in the warehouse and create fact tables (e.g., Fact_Sales), dimension tables (e.g., Dim_Customer, Dim_Item).
CREATE OR ALTER PROCEDURE Sales.LoadDataFromStaging (@OrderYear INT)
AS
BEGIN
-- Load data into the Customer dimension table
INSERT INTO Sales.Dim_Customer (CustomerID, CustomerName, EmailAddress)
SELECT DISTINCT CustomerName, CustomerName, EmailAddress
FROM [Sales].[Staging_Sales]
WHERE YEAR(OrderDate) = @OrderYear
AND NOT EXISTS (
SELECT 1
FROM Sales.Dim_Customer
WHERE Sales.Dim_Customer.CustomerName = Sales.Staging_Sales.CustomerName
AND Sales.Dim_Customer.EmailAddress = Sales.Staging_Sales.EmailAddress
);
-- Load data into the Item dimension table
INSERT INTO Sales.Dim_Item (ItemID, ItemName)
SELECT DISTINCT Item, Item
FROM [Sales].[Staging_Sales]
WHERE YEAR(OrderDate) = @OrderYear
AND NOT EXISTS (
SELECT 1
FROM Sales.Dim_Item
WHERE Sales.Dim_Item.ItemName = Sales.Staging_Sales.Item
);
-- Load data into the Sales fact table
INSERT INTO Sales.Fact_Sales (CustomerID, ItemID, SalesOrderNumber, SalesOrderLineNumber, OrderDate, Quantity, TaxAmount, UnitPrice)
SELECT CustomerName, Item, SalesOrderNumber, CAST(SalesOrderLineNumber AS INT), CAST(OrderDate AS DATE), CAST(Quantity AS INT), CAST(TaxAmount AS FLOAT), CAST(UnitPrice AS FLOAT)
FROM [Sales].[Staging_Sales]
WHERE YEAR(OrderDate) = @OrderYear;
END
EXEC Sales.LoadDataFromStaging 2021- A view (Staging_Sales) that points to the lakehouse.
-
Data Integrity and Performance Consideration:
- Decide whether or not to use foreign key constraints based on the trade-offs between data integrity and performance.
-
Loading Data:
- Create a stored procedure in the warehouse to load data from the lakehouse. This involves extracting and transforming data based on specific criteria, such as the year.
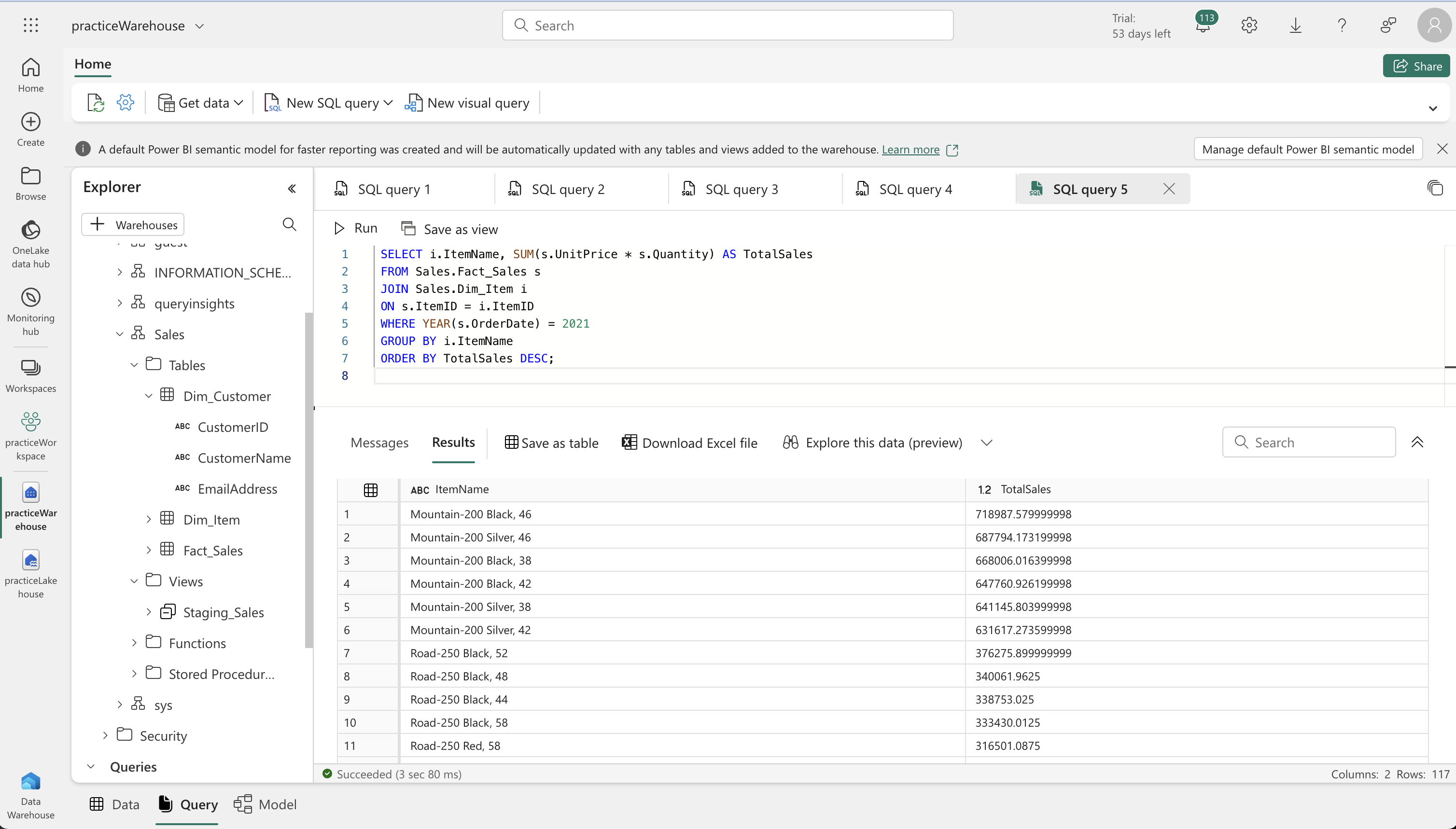
- Running Analytical Queries:
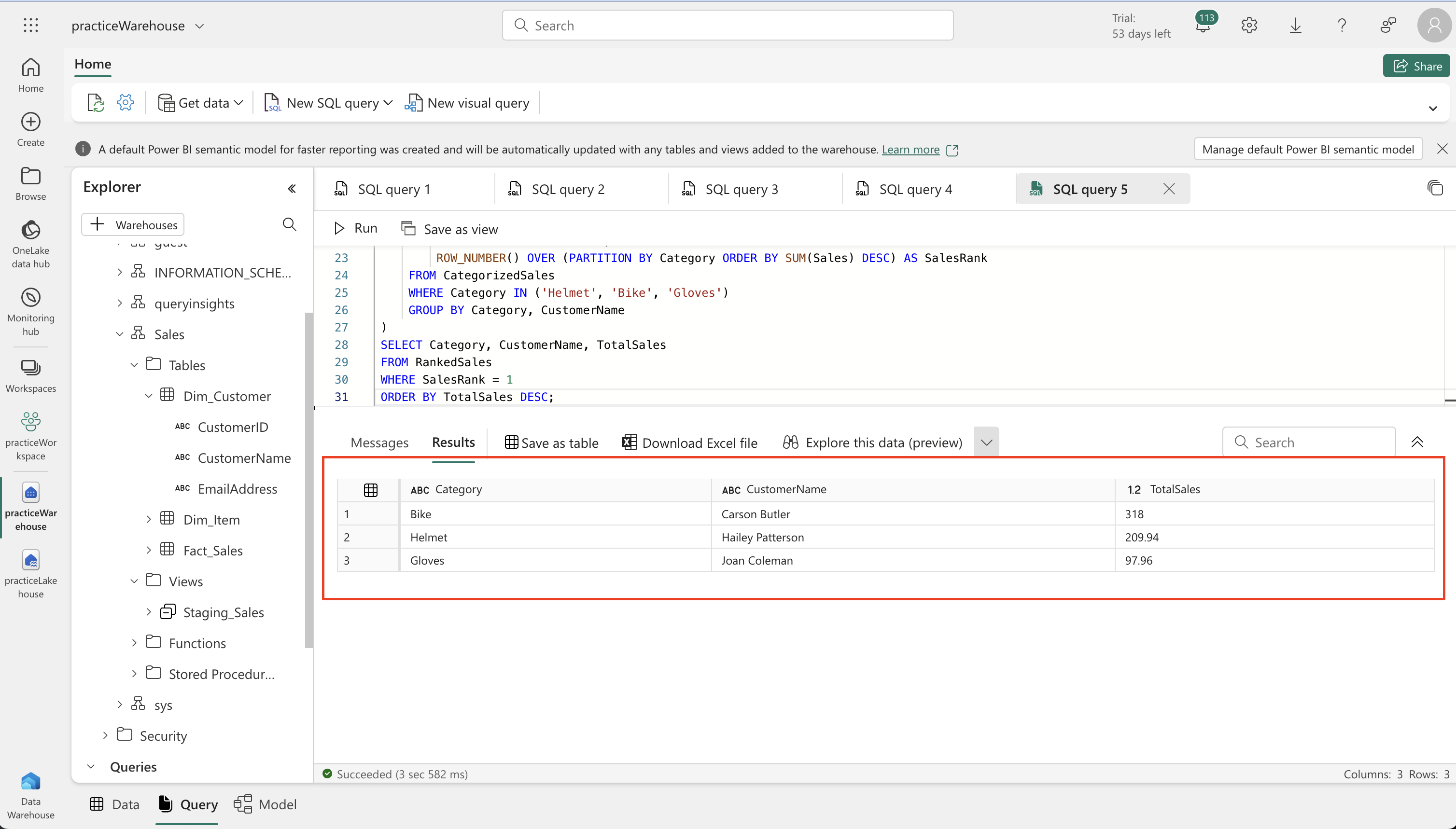
- Execute SQL queries to analyze the data. These queries can include aggregating sales data by customer or item and categorizing sales by item type.
WITH CategorizedSales AS (
SELECT
CASE
WHEN i.ItemName LIKE '%Helmet%' THEN 'Helmet'
WHEN i.ItemName LIKE '%Bike%' THEN 'Bike'
WHEN i.ItemName LIKE '%Gloves%' THEN 'Gloves'
ELSE 'Other'
END AS Category,
c.CustomerName,
s.UnitPrice * s.Quantity AS Sales
FROM Sales.Fact_Sales s
JOIN Sales.Dim_Customer c
ON s.CustomerID = c.CustomerID
JOIN Sales.Dim_Item i
ON s.ItemID = i.ItemID
WHERE YEAR(s.OrderDate) = 2021
),
RankedSales AS (
SELECT
Category,
CustomerName,
SUM(Sales) AS TotalSales,
ROW_NUMBER() OVER (PARTITION BY Category ORDER BY SUM(Sales) DESC) AS SalesRank
FROM CategorizedSales
WHERE Category IN ('Helmet', 'Bike', 'Gloves')
GROUP BY Category, CustomerName
)
SELECT Category, CustomerName, TotalSales
FROM RankedSales
WHERE SalesRank = 1
ORDER BY TotalSales DESC;