
Apache Spark in Microsoft Fabric:
In this article, discover the key features and advantages of using Apache Spark in Microsoft Fabric. Explore its versatile language support, Spark settings, and rich library ecosystem. Learn how Microsoft Fabric seamlessly integrates Spark for interactive analysis and automated data processing, making it a powerful tool for data professionals.


Exploring Sales Data with Apache Spark in Synapse Data Engineering
In this tutorial, we navigate the process of creating a lakehouse in Synapse Data Engineering, a critical component for data analysis and management. The journey begins by downloading a dataset (orders.zip) containing sales data from 2019 to 2021 in CSV format. After uploading these files to the newly created lakehouse, we dive into data exploration using Apache Spark within Synapse.
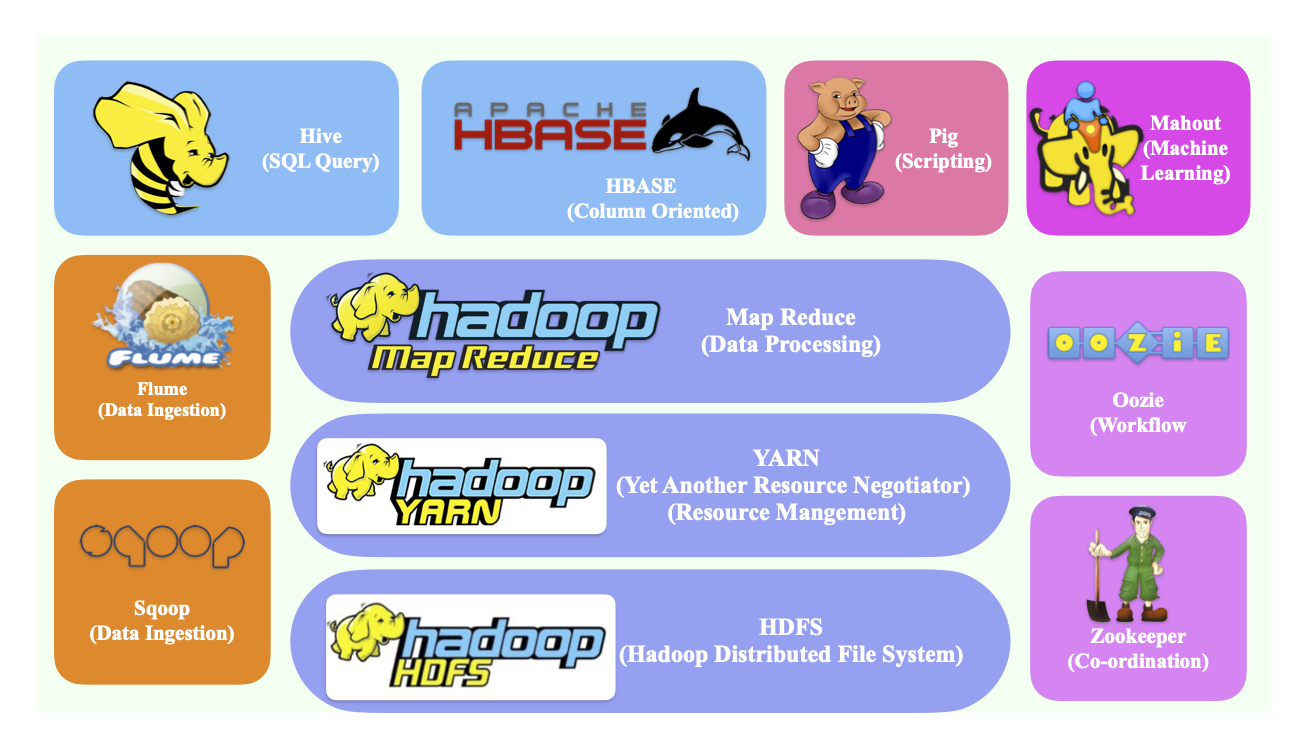
Hadoop Ecosystem
Explore key components categorized for easy understanding. From data storage to seamless workflows, machine learning discover how Hive, HBase, Flume, and more contribute to the world of big data.

Introduction to Hadoop
Breaking down Big Data basics! 📊 Explored structured, unstructured, and semi-structured data. 📊 Explored big data challenges and solutions, spotlighting HDFS and MapReduce Architecture.